
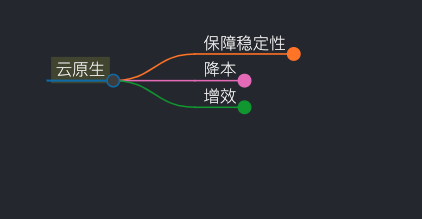
云原生思维导图
从保稳、降本、增效三个方向出发
稳定性就是不出故障,围绕着故障周期,进行梳理。
事前--->事中--->事后
降发生:事前/事后,将异常风险左移
降发生事前:高可用、持续风险治理、持续巡检、持续故障演练(演练库、预案库)、全链路压测、支持灰度发布和快速回滚
小于 1 分钟
从保稳、降本、增效三个方向出发
稳定性就是不出故障,围绕着故障周期,进行梳理。
事前--->事中--->事后
降发生:事前/事后,将异常风险左移
降发生事前:高可用、持续风险治理、持续巡检、持续故障演练(演练库、预案库)、全链路压测、支持灰度发布和快速回滚
Clay、腾讯、字节、美团、滴滴、Vivo等各大公司云原生落地实践 整理汇总
一句话概括:在保证稳定性的前提下,降本增效
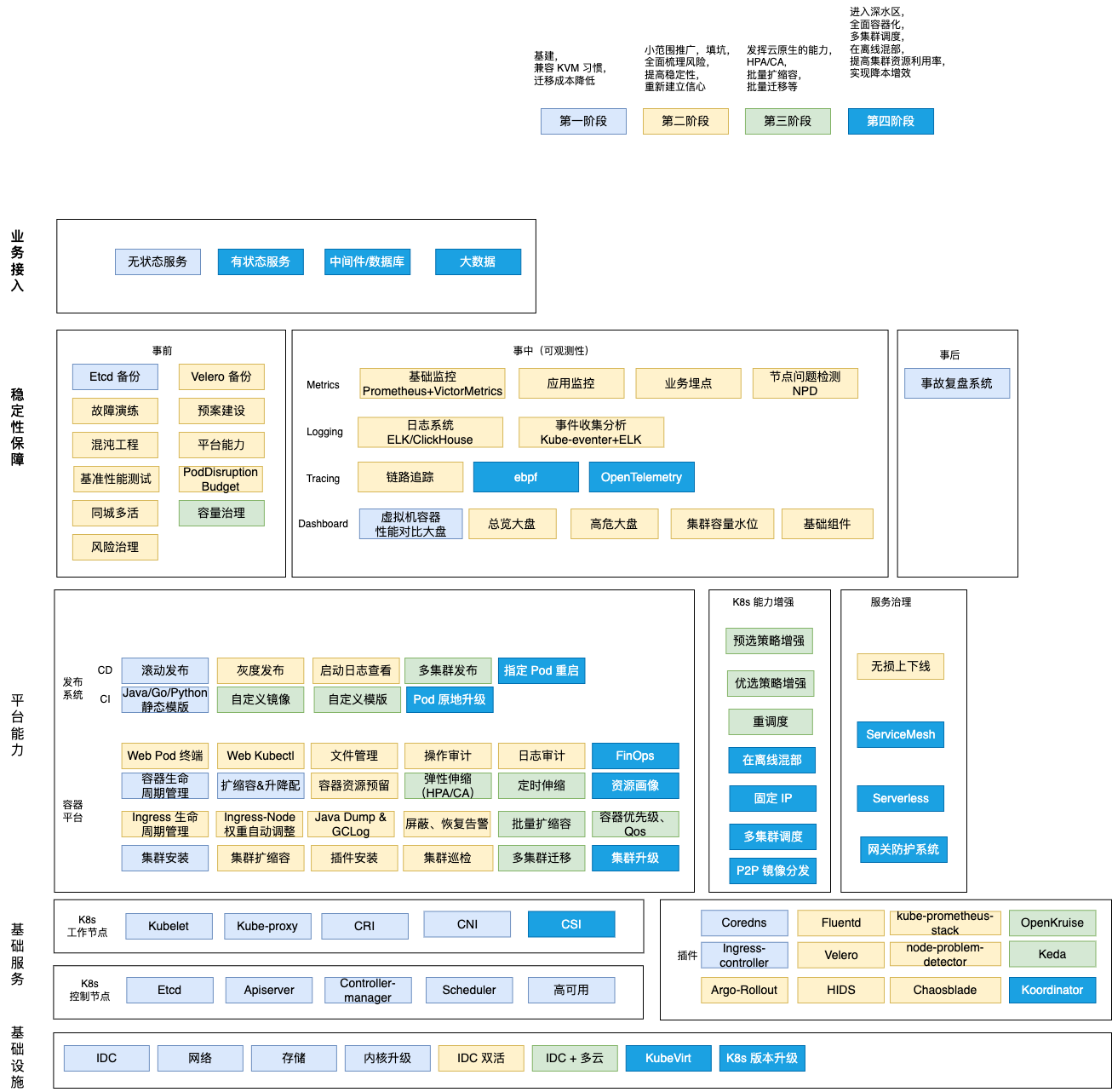
1)项目立项,确定目标,从上到下,从下到上,一同发力。
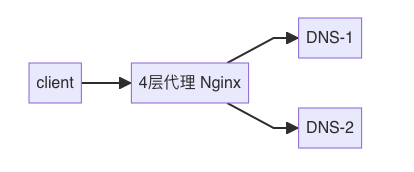
Client 报错
应用的报错日志为:java.net.UnknownHostException:
代理服务报错
本文目录:
顾名思义:负责将 Pod 调度到 Node 上。

架构
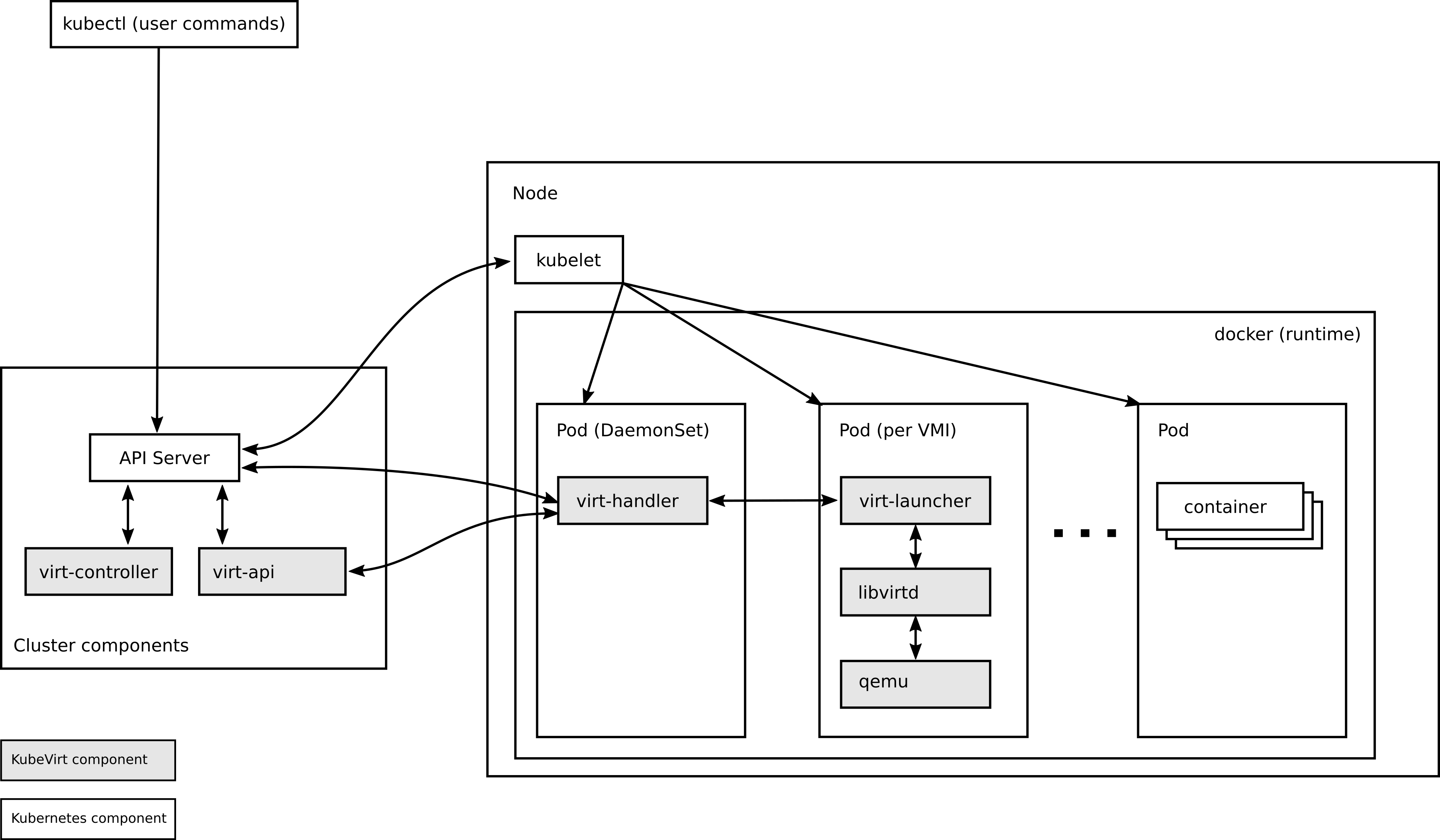
上篇,我们 从0开始装一套 KubeVirt 1.2.1
单点登录失败,但是其他接口正常
问题要点是:单点登录失败,看代码是 request 和 response 的 RedirectUri 不一样导致的。

目前的南北流量架构为:

上篇 “深入了解 kube-scheduler” ,已经知道 kube-scheduler 的工作流程,以及如何实现自定义插件。koordinator 和 crane 都是基于Scheduler Framework 进行实现的 负载感知插件。本文不再赘述,感兴趣可以看上篇文章。
原生 Kubernetes 调度器仅基于资源的 Request 进行调度,在生产环境资源的真实使用率和申请率往往相差巨大,造成资源浪费的同时也会造成节点的负载不均衡。
上次发文 K8s 无备份,不运维,文章开篇,插入了一张 K8s 集群巡检的图片,好多小伙伴私信留言,问我要开源地址。由于其通用性不高,大多数公司需要结合自身的架构情况进行不同的巡检,所以我没有开源。
今天发现有小伙伴还在群里讨论,有没有类似的工具/平台,虽然没有开源,我把其关键的 巡检指标 和 后端核心伪代码 分享出来,供各位同行参考。