
高级 Bash 脚本编程指南
本教程内容转载自:https://github.com/LinuxStory/Advanced-Bash-Scripting-Guide-in-Chinese
感谢开源翻译!!!

大约 5 分钟
本教程内容转载自:https://github.com/LinuxStory/Advanced-Bash-Scripting-Guide-in-Chinese
感谢开源翻译!!!
| 博客地址 | 简介 |
|---|---|
| 敖小剑的博客 | 资深码农,十九年软件开发经验,微服务专家,Service Mesh布道师,Servicemesher社区联合创始人,Dapr Maintainer |
| 骏马金龙 | 运维开发,Ansible专栏:一步到位玩透Ansible 作者 |
| https://lework.github.io/ | |
| 杜屹东的博客 | 亚马逊解决方案架构师、前阿里工程师,全栈、devops |
| 苏易北 | 公有云从业者,坐标深圳。Go / Python / Shell / C,专注云计算、虚拟化领域相关实践 |
| mrhope | 物理专业的大佬,vuepress-theme-hope主题作者 |
| 二丫讲梵 | 博客朋友李启龙的博客,内容十分优质,国内最全的nexus系列文档 |
| willseecloud | 优秀的运维笔记 |
| 张种恩的技术小栈 | |
| Java 全栈知识体系 | |
| CTC的运维学习笔记 | |
| Find the Best Programming Courses & Tutorials | |
经济高速发展的今天,我们处于信息大爆炸的时代。随着经济发展,信息借助互联网的力量在全球自由地流动,于是就催生了各种各样的服务平台和软件系统。

由于业务的多样性,这些平台和系统也变得异常的复杂。如何对其进行监控和维护是我们 IT 人需要面对的重要问题。就在这样一个纷繁复杂地环境下,监控系统粉墨登场了。
今天,我们会对 IT 监控系统进行介绍,包括其功能,分类,分层;同时也会介绍几款流行的监控平台。
从保稳、降本、增效三个方向出发
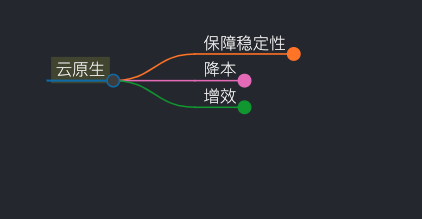
稳定性就是不出故障,围绕着故障周期,进行梳理。
事前--->事中--->事后
降发生:事前/事后,将异常风险左移
降发生事前:高可用、持续风险治理、持续巡检、持续故障演练(演练库、预案库)、全链路压测、支持灰度发布和快速回滚
Clay、腾讯、字节、美团、滴滴、Vivo等各大公司云原生落地实践 整理汇总
一句话概括:在保证稳定性的前提下,降本增效
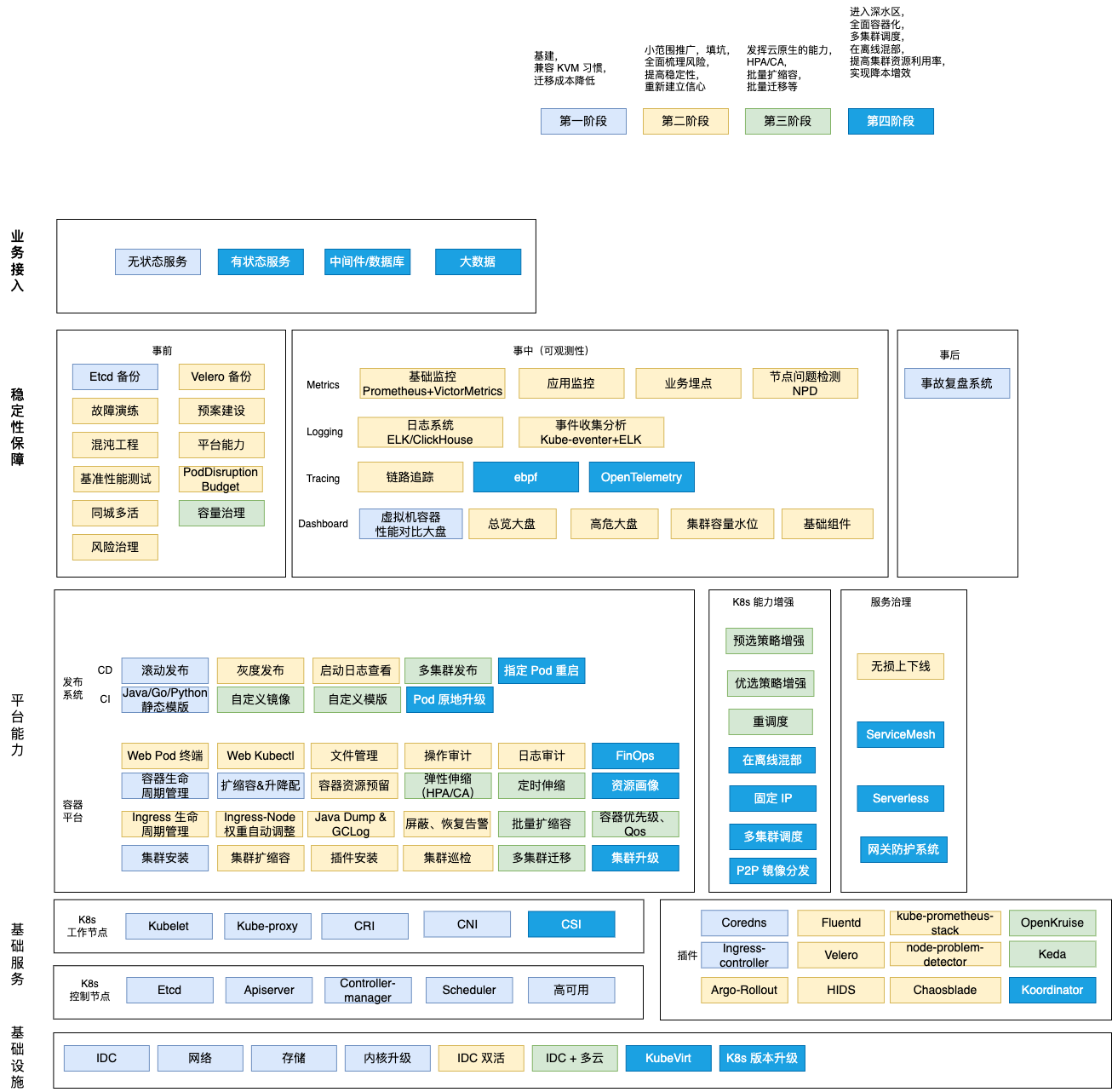
1)项目立项,确定目标,从上到下,从下到上,一同发力。
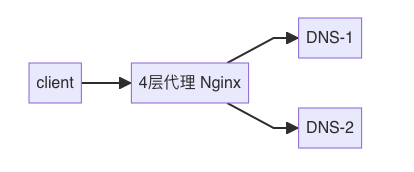
Client 报错
应用的报错日志为:java.net.UnknownHostException:
代理服务报错