
K8s 驱逐场景以及规避方案
K8s 驱逐场景以及规避方案
Pod 驱逐场景总结
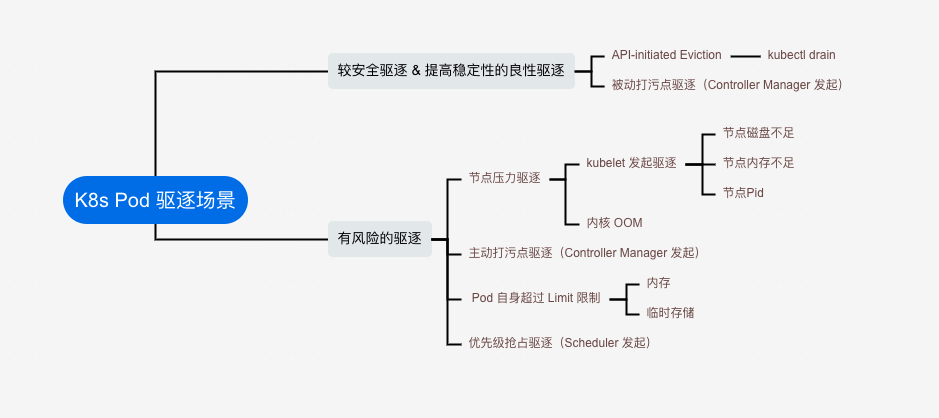
从一个 SRE 角度看, Pod 驱逐分为两种情况:
- 较安全驱逐 & 提高稳定性的良性驱逐
- API 发起驱逐,典型案例:kubectl drain
- Node Not Ready 时,Controller Manager 发起的驱逐
- 有风险的驱逐
- 节点压力驱逐
- 节点磁盘空间不足、内存不足 或 Pid 不足, kubelet 发起驱逐
- 节点内存不足,内核发起 OOM
- 节点打污点(NoExecute),导致 Pod 被驱逐,或者移除亲和性标签,导致 Pod 被驱逐, Controller Manager 发起的驱逐
- Pod 超过自身 Limit 限制, 内核用满,临时存储用满等
- 优先级抢占驱逐
- 节点压力驱逐
概述一下各场景
kubect drain
drain ~= cordon + delete Pod
主动驱逐,受限于 PDB,如果配置了 PDB,会防止应用出现全部不可用的状况,但是直接 操作 DELETE Pod ,不受 PDB 限制,所以 drain 比 直接 DELETE 会安全一些,当做节点维护时。
配置 PDB,进一步提高服务整体可用性
Node Not Ready
节点会被打上 node.kubernetes.io/unreachable:NoExecute 的污点,上面的 Pod 会被驱逐。
可以 kubectl describe node 进行定位
Kubelet 发起驱逐
主要是节点不可压测资源不足造成,这里分析下 内存不足的情况下:
- 首先考虑资源使用量超过其请求的
BestEffort或BurstablePod。 这些 Pod 会根据它们的优先级以及它们的资源使用级别超过其请求的程度被逐出。 - 资源使用量少于请求量的
GuaranteedPod 和BurstablePod 根据其优先级被最后驱逐。
可根据事件日志快速定位到
内核 OOM
只看进程的 oom_score, 优先 kill oom_score 较高的,不通服务 的 Qos 设置可能会影响 oom_score,但不能 保证不被 kill。
内核 OOM 日志,可以从 dmesg 中查到, 可以配置 NPD 快速发现 内核 OOM 事件
内核 OOM,一般情况,Pod 不会重新调度,只会原地重启
超过 Limit 限制
超过 cgroup 限制,会被强制杀掉
可根据事件日志快速定位到
打 NoExecute 污点,或者移除标签,导致标签选择失败
Controller Manager 控制器,循环监听 Node 、Pod 信息,然后持续调谐
抢占驱逐
Pod 分配调度时,节点资源不足,Scheduler 发起的驱逐,低优先级 Pod 腾出资源给 高优先级 Pod 调度
如何规避发生 风险驱逐
总结:
- 配置 PDB + NPD ,进一步提高服务可用性,缩短问题定位时间
- 根据 USE 法则,配置 Node 内存、磁盘、PID等 使用率、饱和度 等监控报警
- 配置优先级策略时,考虑是否要抢占 低优先级 资源,如果不想发生意外驱逐,配置 preemptionPolicy 为 Never;应用在申请或控制资源时,前置准入控制,查看当然 request 值水位,控制到安全水位,资源不足时,扩充 Node 后,才允许申请扩容
- 容器 内存黑洞是一个比较难处理的问题,目前就是 调整 JVM 参数 + Pod 资源使用情况 配置监控告警
- 打污点 和 移除标签 要慎重,尽快 手工驱逐后,再操作,避免非预期情况发生
我是 Clay,下期见 👋
欢迎订阅我的公众号「SRE运维进阶之路」或关注我的 Github https://github.com/clay-wangzhi/SreGuide 查看最新文章
欢迎加我微信
sre-k8s-ai,与我讨论云原生、稳定性相关内容
