
K8s 一条默认参数引起的性能问题
K8s 一条默认参数引起的性能问题
👉 Nodejs 应用 从虚拟机迁移到容器 产生的性能问题
问题时间线
[xx:xx] 开发收到业务反馈接口响应超时
[xx:xx] 开发&SRE&中间件 联合排查代码、网关、底层网络问题,无果
[xx:xx] 测试环境复现排查
[xx:xx] 利用差异法、排除法和经验解决,先上线
[xx:xx] 根因定位
问题现象
1)接口偶发性超时
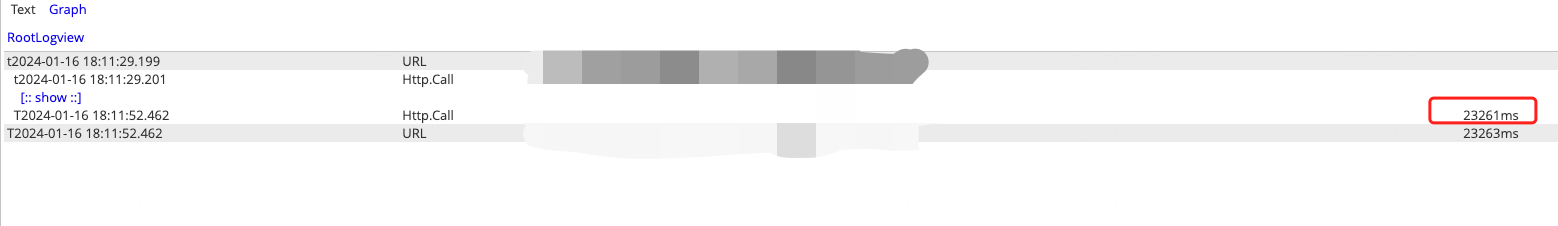
2)容器化后,CPU 使用率一直较高
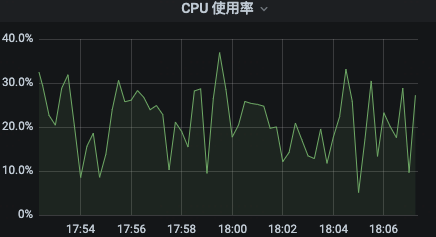
3)迁移到容器前,虚拟机 CPU 使用率和接口响应均正常
问题排查
首先使用排除法: 确定了与网络、代码没有关系
然后进行差异分析:
在虚拟机上启动相同应用做测试,结果正常,矛头直指容器 😱
在 Serverless 测试集群上跑了一下,也正常,开始疑惑,是容器的问题吗 🤔
思考:
- 容器对比虚拟机,应用运行环境发生了哪些改变呢 → 经验告诉我:Service 环境变量 会自动注入到 Pod 里面
- 为啥 Serverless 集群没有问题呢 → 量 ,常规集群所跑的应用数量多,Service 环境变量的数目自然会多
检验:
- 进入常规集群 Pod 查看环境变量的数目
env | wc -l, 结果有 1.6 w 个环境变量,基本都是 Service 自动注入的 - 关闭 Service 自动注入参数,
enableServiceLinks: false,测试检验,CPU 使用率回归正常,接口响应正常
根因分析
👍 优先解决问题,事后再深挖根因!
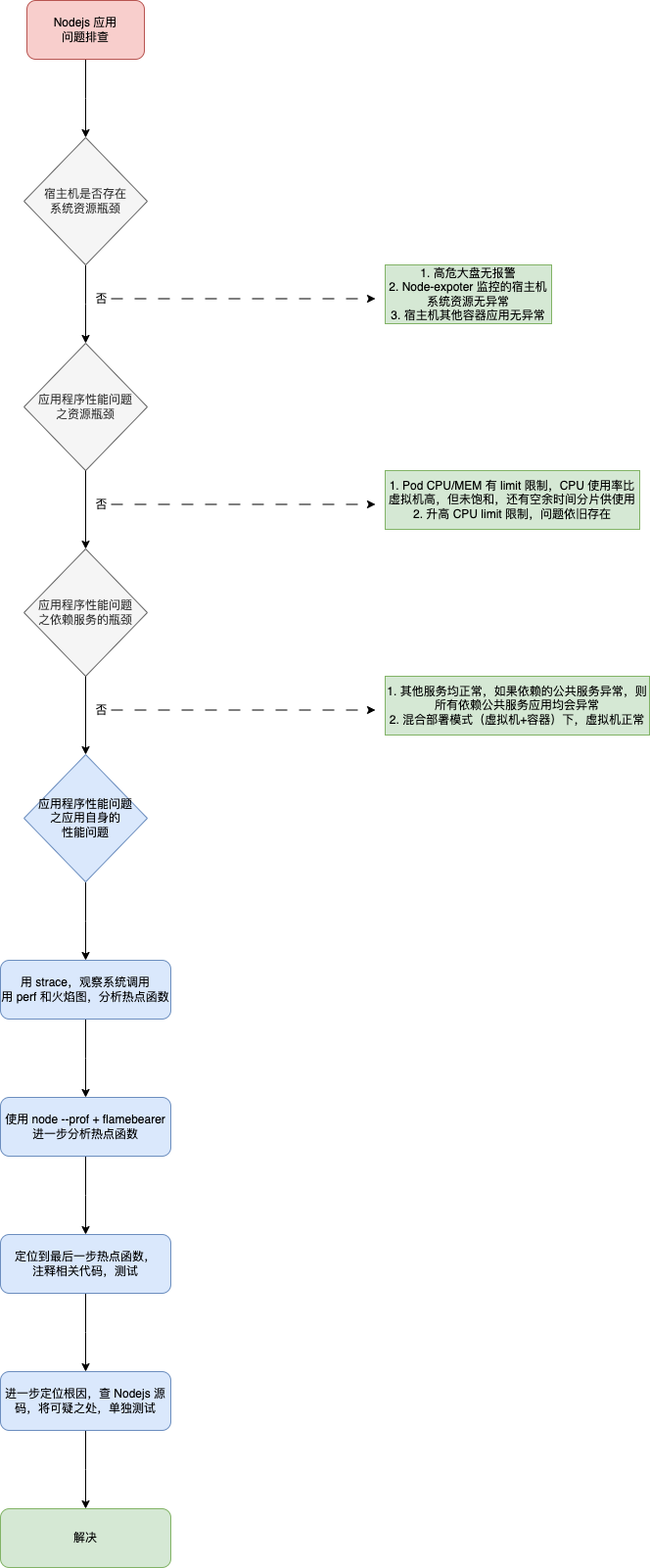
分析性能的一般步骤
系统资源瓶颈
系统资源的瓶颈,可以通过 USE 法,即 使用率、饱和度以及错误数这三类指标来衡量。系统的资源,可以分为硬件资源和软件资源两类。
如 CPU、内存、磁盘和文件系统以及网络等,都是最常见的硬件资源。
而文件描述符数、连接跟踪数、套接字缓冲区大小等,则是典型的软件资源。
应用程序瓶颈
最典型的应用程序性能问题,就是吞吐量(并发请求数)下降、错误率升高以及响应时间增大。
本质来源,实际上只有三种,也就是资源瓶颈、依赖服务瓶颈以及应用自身的瓶颈。
第一种资源瓶颈, CPU、内存、磁盘和文件系统 I/O、网络以及内核资源等各类软硬件资源出现了瓶颈,从而导致应用程序的运行受限。
第二种依赖服务的瓶颈,也就是诸如数据库、分布式缓存、中间件等应用程序,直接或者间接调用的服务出现了性能问题,从而导致应用程序的响应变慢,或者错误率升高。这说白了就是跨应用的性能问题,使用全链路跟踪系统,就可以帮你快速定位这类问题的根源。
最后一种,应用程序自身的性能问题,包括了多线程处理不当、死锁、业务算法的复杂度过高等等。对于这类问题,通过应用程序指标监控以及日志监控,观察关键环节的耗时和内部执行过程中的错误,就可以帮你缩小问题的范围。
不过,由于这是应用程序内部的状态,外部通常不能直接获取详细的性能数据,所以就需要应用程序在设计和开发时,就提供出这些指标,以便监控系统可以了解应用程序的内部运行状态。
如果这些手段过后还是无法找出瓶颈,你还可以用系统资源模块提到的各类进程分析工具,来进行分析定位。比如:
你可以用 strace,观察系统调用;
使用 perf 和火焰图,分析热点函数;
甚至使用动态追踪技术,来分析进程的执行状态。
具体排查过程
针对本文的案例,排查思路如下:
问题现象追踪
通过 「容器速查大盘」 实时查看 CPU 利用率
通过
time+curl命令实时测试 API 响应耗时情况for i in `seq 1 100`; do time curl -I ${API} ; done
使用 strace 、 perf 排查
# 在Master节点,查询 Pod 所在宿主机
kubectl -n work describe ${PodName} | grep 'Node:' | awk -F/ '{print $2}'
# 在Master节点,查询 ContainerID
kubectl -n work get pod ${PodName} -o template --template='{{range .status.containerStatuses}}{{.containerID}}{{end}}' | sed 's/docker:\/\/\(.*\)$/\1/'
# 在 Pod 所在宿主机,查询 Pid
docker inspect -f {{.State.Pid}} ${ContainerID}
# 查询是否有子进程,层层找出 CPU 占用高的子进程
pstree -p ${Pid}
ps -aux | head -1; ps -aux | grep ${Pid}
# 在 Pod 所在宿主机,使用 strace 观察系统调用
## -f表示跟踪子进程和子线程,-T表示显示系统调用的时长,-tt表示显示跟踪时间
strace -f -T -tt -p ${Pid} -o trace.log
# 请求五次接口,观察响应情况
date +"%H:%M:%S"; time curl -I ${API} ; date +"%H:%M:%S"
## 五次请求的时间有用信息如下,会发现第一次和第五次请求耗时较长,20s 左右, 其他三次响应很快,80ms 左右
15:19:40
20.055 total
15:20:00
15:20:05
0.090 total
15:20:05
15:20:07
0.084 total
15:20:07
15:20:09
0.078 total
15:20:09
15:20:13
19.164 total
15:20:33
## trace.log 分析
### 过滤关键信息,五次处理 uri 的时间,发现第一次和第五次的请求被阻塞了
31366 15:19:59.980073 read(21, "HEAD /xxx"..., 65536) = 134 <0.000016>
31366 15:20:05.345321 read(21, "HEAD /xxx"..., 65536) = 134 <0.000014>
31366 15:20:07.373577 read(21, "HEAD /xxx"..., 65536) = 134 <0.000013>
31366 15:20:09.209124 read(21, "HEAD /xxx"..., 65536) = 134 <0.000013>
31366 15:20:33.190620 read(21, "HEAD /xxx"..., 65536) = 134 <0.000025>
### 过滤关键信息,查询哪里造成的阻塞,发现两次超时请求前,都有 futex resumed,并且进程 ID 不同,是31366的子进程
#### futex 是 Linux 系统上用于实现用户空间线程同步的一种机制。这些记录显示进程可能在等待或释放某种锁或同步对象
31371 15:19:59.979948 <... futex resumed>) = 0 <0.000069>
31366 15:19:59.979961 <... futex resumed>) = 0 <0.000068>
31372 15:19:59.979977 <... futex resumed>) = 0 <0.000033>
31366 15:19:59.980023 write(16, "\1\0\0\0\0\0\0\0", 8) = 8 <0.000011>
31366 15:19:59.980073 read(21, "HEAD /xxx"..., 65536) = 134 <0.000016>
31372 15:20:33.189971 <... futex resumed>) = 0 <0.000063>
31366 15:20:33.189985 <... futex resumed>) = 0 <0.000049>
31373 15:20:33.190001 <... futex resumed>) = 0 <0.000033>
31366 15:20:33.190017 read(24, "\0\0\0002\0\0001\261\0\0\0\1\0\nnodejs_log\0\0\0\1\0\0\0\2"..., 65536) = 216 <0.000019>
31366 15:20:33.190081 munmap(0x7f166db42000, 69632) = 0 <0.000044>
31366 15:20:33.190620 read(21, "HEAD /man-hour-price/get-busines"..., 65536) = 134 <0.000025>
### 过滤关键信息,阻塞的时候能看懂的其他关键,发现有两个执行系统命令,和超时的次数及时间吻合
19623 15:19:44.169724 execve("/bin/sh", ["/bin/sh", "-c", "free -m"], 0x7f166b53b230 /* 13793 vars */ <unfinished ...>
20616 15:19:51.988739 execve("/bin/sh", ["/bin/sh", "-c", "df -k '/'"], 0x7f166b53b340 /* 13793 vars */ <unfinished ...>
21542 15:19:59.799328 execve("/bin/sh", ["/bin/sh", "-c", "df -k '/data'"], 0x7f166b53b450 /* 13793 vars */ <unfinished ...>
23324 15:20:17.371918 execve("/bin/sh", ["/bin/sh", "-c", "free -m"], 0x7f166b53b7a0 /* 13793 vars */ <unfinished ...>
24160 15:20:25.186710 execve("/bin/sh", ["/bin/sh", "-c", "df -k '/'"], 0x7f166b53b0d0 /* 13793 vars */ <unfinished ...>
24791 15:20:32.997766 execve("/bin/sh", ["/bin/sh", "-c", "df -k '/data'"], 0x7f166b53b200 /* 13793 vars */ <unfinished ...>
strace 排查发现:子进程执行同步任务阻塞了主进程,子进程里面执行系统命令free 和 df
# strace 命令找不到具体的热点函数,此时 perf 上,看火焰图
perf record -a -g -p {$PID} -- sleep 60
git clone https://github.com/brendangregg/FlameGraph
cd FlameGraph/
perf script -i /root/perf.data | ./stackcollapse-perf.pl --all | ./flamegraph.pl > ksoftirqd.svg
# 将 ksoftirqd.svg 传输到本地,用浏览器打开,如下,发现找不到具体的热点函数

使用 nodejs --prof + flamebearer 排查
# 进入容器
kubectl -n work exec -it ${PodName} -- /bin/sh
# 修改启动端口, 找到 app.listen 修改,然后再启动一个实例
node /data/node_modules/.bin/cross-env NODE_ENV=work node --prof --jitless --no-lazy src/main
# 运行一段时间,生成火焰图,在浏览器打开
npm install -g flamebearer --registry=https://registry.npmmirror.com
node --prof-process --preprocess -j isolate*.log | flamebearer
# 将 flamegraph.html 传输到本地,用浏览器打开,如下
根据 strace 排查到的 子进程会执行系统命令,查看可能相关联的函数

通过 flamebearer 可以定位定最后是 child_process.js 文件中函数的相关调度, execSync --> spawnSync --> normalizeSpawnArguments
首先再上一层的文件清楚的标记出来是 System.js 调度产生的热点,第一步现将这个调度注释掉,启动观察,发现,应用恢复正常。
源码分析,单独测试
查看 nodejs 源码,查询可能造成阻塞耗时的地方,https://github.com/nodejs/node/blob/v14.x/lib/child_process.js#L485
可以发现这个函数,最可疑的是这个地方
const env = options.env || process.env;
const envPairs = [];
// Prototype values are intentionally included.
for (const key in env) {
const value = env[key];
if (value !== undefined) {
envPairs.push(`${key}=${value}`);
}
}
在 Pod 里面,单独执行这段代码,统计耗时
const env = process.env;
const envPairs = [];
console.time('TestEnv');
for (const key in env) {
const value = env[key];
if (value !== undefined) {
envPairs.push(`${key}=${value}`);
}
}
console.timeEnd('TestEnv')
输出结果为:TestEnv: 7.494s
果然是它✌️
进一步分析,这里面影响性能的因素有两个
pObject 的实现,我测试 len 为 2w 的map,耗时才 38msrocess.env - 本身在 js 中 for-in 循环的性能就是最差的
解决办法
有以下几种办法可以解决,任选其一即可:
- 将 YAML 文件中 enableServiceLinks 置为 false ,禁止向 Pod 自动注入 Service 环境变量
- child_process.execSync 以同步的方式衍生子进程, 会阻塞 Node.js 事件循环,在大多数情况下,同步的方法会对性能产生重大影响,可以使用 child_process.exec 改为异步方法
- child_process.execSync 调用时,指定需要的 env 传进去,不要用默认的系统 env ,https://github.com/nodejs/node/blob/v14.x/lib/child_process.js#L586
总结
应用性能问题,放到一遍,在 K8s 层面,有坑需要我们额外注意
enableServiceLinks 参数 默认为开启状态,但是大多数情况我们是不需要的,笔者建议统一关闭,有 DNS 的情况下,没多大用途,也有相关 issue 提出将 enableServiceLinks 默认值改为 false
如果不需要服务环境变量(因为可能与预期的程序冲突,可能要处理的变量太多,或者仅使用DNS等),则可以通过在 pod spec 上将 enableServiceLinks 标志设置为 false 来禁用此模式。
Nodejs 和 K8s 针对此问题的相关 issue
- https://github.com/nodejs/node/issues/3104
- https://github.com/kubernetes/kubernetes/issues/60099
- https://github.com/kubernetes/kubernetes/issues/121787
参考链接:
k8s doc : https://kubernetes.io/docs/tutorials/services/connect-applications-service/
倪朋飞 「Linux性能优化实战」
flamebearer:https://github.com/mapbox/flamebearer