
云原生业界对标 & 落地实践
云原生业界对标 & 落地实践
Clay、腾讯、字节、美团、滴滴、Vivo等各大公司云原生落地实践 整理汇总
Clay[1]
企业落地云原生的目的
一句话概括:在保证稳定性的前提下,降本增效
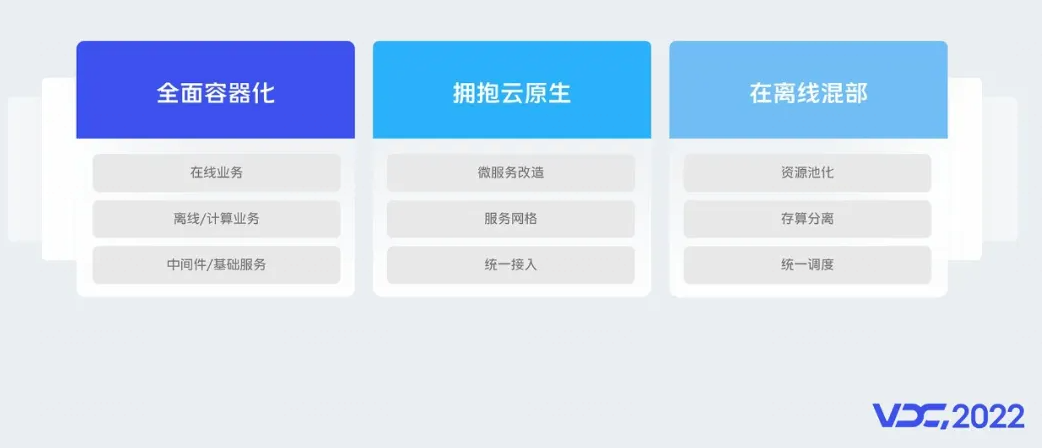
云原生能力全景图
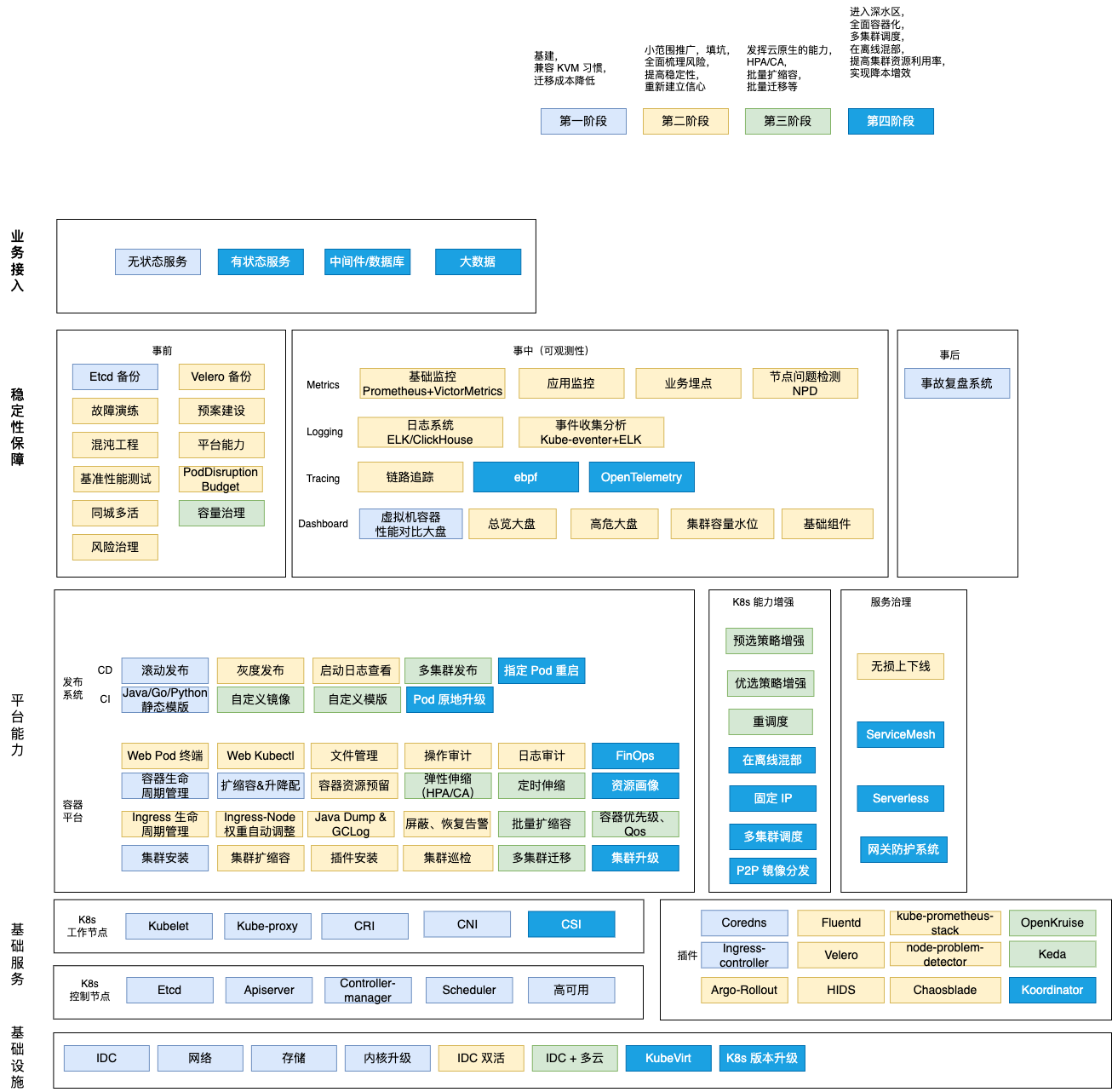
推广方法论
1)项目立项,确定目标,从上到下,从下到上,一同发力。
2)目标拆解,具体到各负责人,建立双周会,定期沟通同步进展。
3)先搞出个试点,最佳实践,然后 点--> 线--> 面 推广。
4)风险可控:采取小步快跑,敬畏生产的策略。
Work --> Test --> UT --> Prod 灰度 --> Prod 全量; 非核心-->核心;提前制定好应急方案。
腾讯[2]
这场技术改造,难点在哪里?
全面上云腾讯不是第一家,但腾讯是拥有最复杂的业务场景的一家,在这个过程中,需要结合业务制定各种各样的技术方案,来满足不同的业务诉求。
在自研业务上云之前,腾讯的每一个业务都有自己完整的技术栈,内部业务在一定程度上形成了“部门墙”效应。这样的改造,过程中既有高层的推进、动员,也有执行层的博弈、妥协,最终实现了用一个点调动全局,让全公司的技术团队得到了一次很好的穿透对齐,让分散的技术能力得以统一。
“像下一盘棋”
2018 年底腾讯开了一次高层决策会议,决定将公司内部所有平台合到一起推行 K8s,开始进行彻底的技术更新换代。
这个事情一开始由邹辉领导的 TKE 团队牵头。TKE 团队主要由一批资深技术人员构成,成员基本都在 30 岁以上,资历以 10 级、11 级为主,团队对成员的技术能力和业务理解能力要求很高。
现在要将所有东西都统一到标准的公有云 TKE 上去,其实内部技术团队难免会心生疑惑:你们是不是要过来抢我们的活?
制定了开源协同技术战略,把公司内部所有做相似事情的团队整合在一起,采取类似于外部开源运作的方式协同工作。这样既解决了技术浪费的问题,又可以去中心化,保持快速响应,还能更好地满足业务需求。
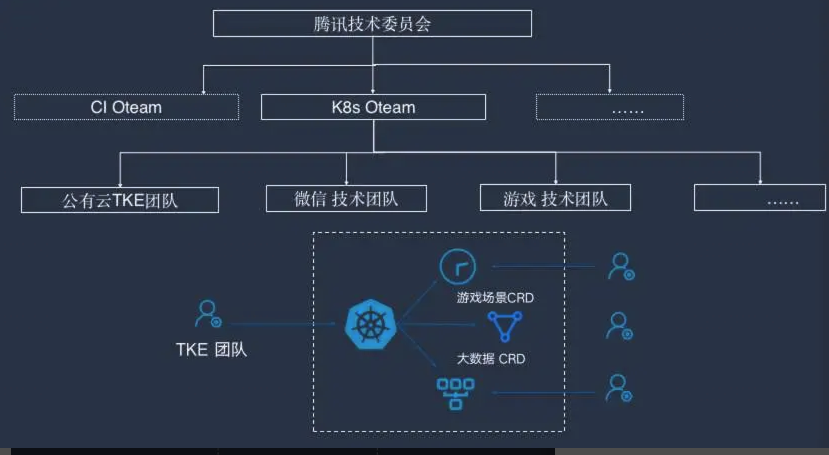
在解决了技术团队的顾虑之后,腾讯从高层开始推进,说服自研业务团队上云,同时打通职级晋升体系,通过设置公司级的专项大奖、普及云原生知识、改造进度榜单晾晒等,从多个方面入手提高大家积极性,依照三年规划,有步骤地进行云原生改造和上云。
腾讯云原生底座的“养成”计划
TKE 平台在初期选择的更多还是一些无状态的业务,先让这些无状态的业务能够快速搬到云上完成改造。
腾讯自研业务需要满足灰度发布的要求。
同时 TKE 也给业务提供了一些虚拟机提供不了的能力,比如动态路由能力。
另外一个好处则是弹性伸缩和健康感知。
还有就是成本上的优势。
提高镜像分发的效率,不仅仅是有益于游戏场景。在一些 AI 训练场景中,镜像甚至更大,几十 GB 也不少见。
另一个不得不提的是原地升级的能力。
这么一个指标去做一键扩缩容的功能。
深水区的那些痛
腾讯花了一年半的时间,将无状态业务搬到了云原生平台,几乎把能踩的坑都踩了一遍,为后续其他业务上云铺平了道路。
同时在一些业务层面,一些有状态的业务,比如说像 Redis 数据库、中间件、一些大数据的套件,也做了原生改造,逐步搬到了整个云原生平台上来。
在这个过程中,TKE 团队在调度层面做了大量的工作。
沉淀多集群管理能力
最近整个社区,包括腾讯主要投入做多集群的管理。单集群做得更小,比如说两千个节点,甚至几百个节点就行;但是让更多的集群组合在一起,通过多集群的调度管理,让它看起来像一个集群,通过这种方式去扩展整个底层资源池的规模。
所有这些多集群编排能力都是基于腾讯云的 Clusternet 开源项目来建设。
进一步提升资源利用率,难度也不断加大
在不断提升资源利用率时,你会发现,这其中大部分的时间都必须跟内核打交道。
当将所有资源都合并到一起后,就会存在有机型代次差异的不同服务器硬件,而不同代次的机型,算力是不一样的,如果同一个工作负载的不同 Pod 位于不同代次的机器上,这就可能导致不同 Pod 的负载极其不均衡。
为了让业务更加充分地利用不同可用区域的资源,能够灵活地在不同可用区之间调度,甚至做到业务不感知可用区域的属性。**彻底屏蔽 K8s 节点、集群、可用区的概念,**分利用不同可用区的资源,同时让业务具备跨区域容灾能力。
云原生路线图
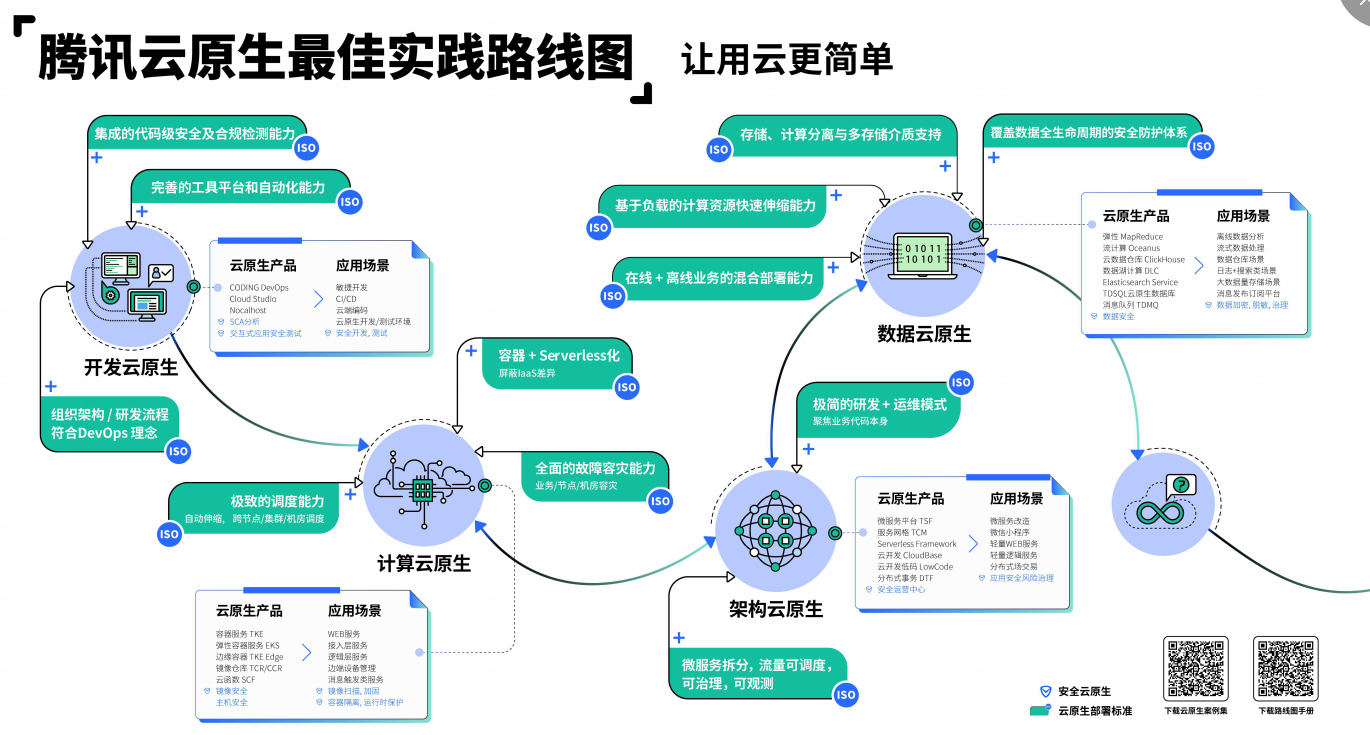
字节[3]
字节云原生推进历程
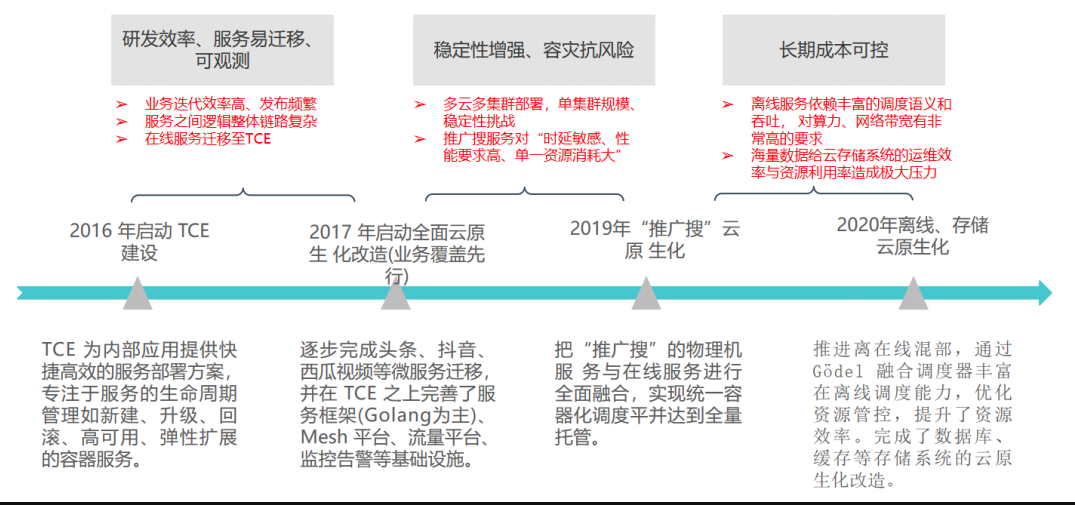
2016 年:启动 自研云引擎(TCE 平台)建设 。 它早期的定位是为内部应用提供快捷高效的服务部署方案,专注于服务的生命周期管理,如创建、升级、回滚、高可用、弹性扩展的容器服务,该阶段的宗旨是快速地支持研发效率、服务易迁移、可观测性等基础能力。
2017 年:启动全面云原生化改造 。在这一阶段,我们完成了今日头条、抖音、西瓜视频等微服务的全量上容器,同时基于自研云平台基础,我们构建并完善了服务框架(Golang 为主)、Mesh 平台、流量平台、监控告警等基础设施。
2018 年 :微服务架构升级。完成核心业务微服务迁移,并在 TCE 之上构建服务框架、Mesh、监控告警等基础设施;
2019年:“推广搜”云原生化 。这一阶段对“推广搜”为主的物理机服务进行了容器化改造,完成了在线服务体系的全量上云。随着字节业务规模的扩展、业务种类的日趋繁多,集群的维护、稳定性、安全等受到了极大挑战,此阶段更关注集群的稳定性、容灾、抗风险等能力。
2020 年:离线、存储云原生化 。我们推进了离在线混合部署,并且通过字节跳动自研融合调度器丰富在离线调度能力,进一步融合在离线业务体系,优化资源管控,提升了资源效率。
当实施离在线混合部署时,我们往往需要强大的调度器来实现离线业务和在线业务友好共存。事实上,公司早期发展阶段通常不具备完善的技术体系和能力,因此字节如何实现离在线混合部署也历经了一段演进路径,如下图所示:
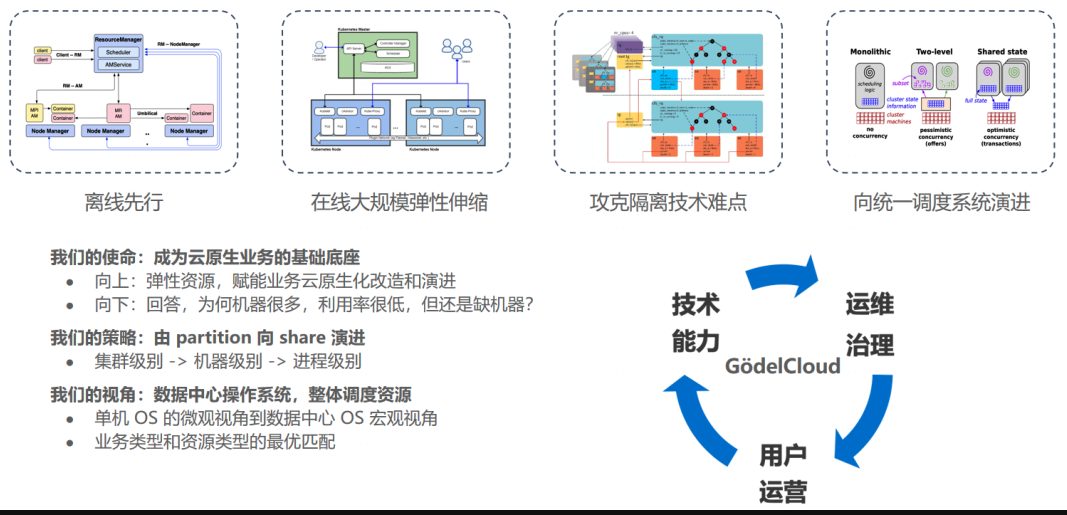
2021 年 :联邦化多集群演进。从资源多云到应用多云,实现全场景应用编排和资源管理的标准化和统一化。
目前基础架构的重点建设领域是 基于联邦化的多集群资源的统一管理和统一调度 。
美团[4]
背景与现状
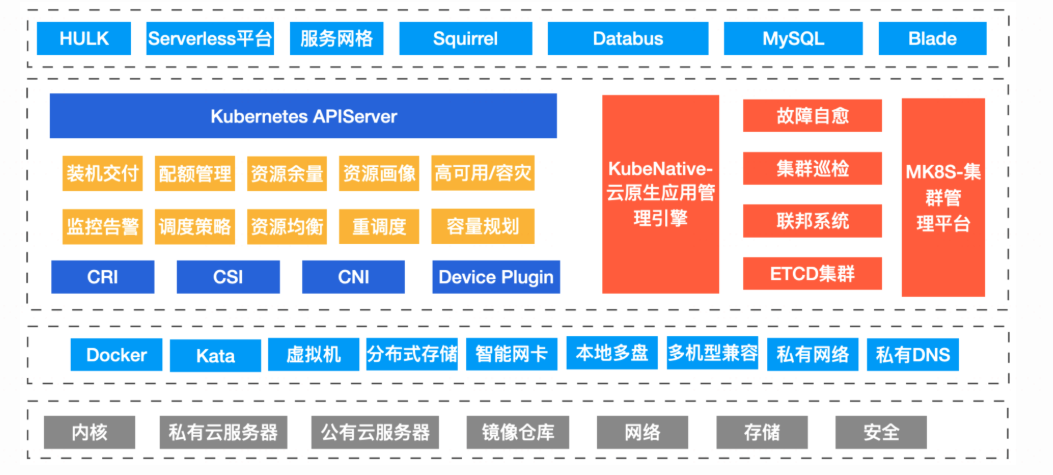
构建了以Kubernetes为核心的统一的资源管理系统
OpenStack到Kubernetes转变的障碍和收益
在OpenStack云平台时期,我们面临的主要问题包括以下几个方面:
- 架构复杂,运维和维护比较困难:OpenStack的整个架构中计算资源的管理模块是非常庞大和复杂,问题排查和可靠性一直是很大的问题。
- 环境不一致问题突出:环境不一致问题是容器镜像出现之前业界的通用问题,不利于业务的快速上线和稳定性。
- 虚拟化本身资源占用多:虚拟化本身大概占用10%的宿主机资源消耗,在集群规模足够大的时候,这是一块非常大的资源浪费。
- 资源交付和回收周期长,不易灵活调配:一方面是整个虚拟机创建流程冗长;另一方面各种初始化和配置资源准备耗时长且容易出错,所以就导致整个机器资源从申请到交付周期长,快速的资源调配是个难题。
- 高低峰明显,资源浪费严重:随着移动互联网的高速发展,公司业务出现高低峰的时间越来越多,为了保障服务稳定不得不按照最高的资源需求来准备资源,这就导致低峰时资源空闲严重,进而造成浪费。
风险控制和可靠性保障
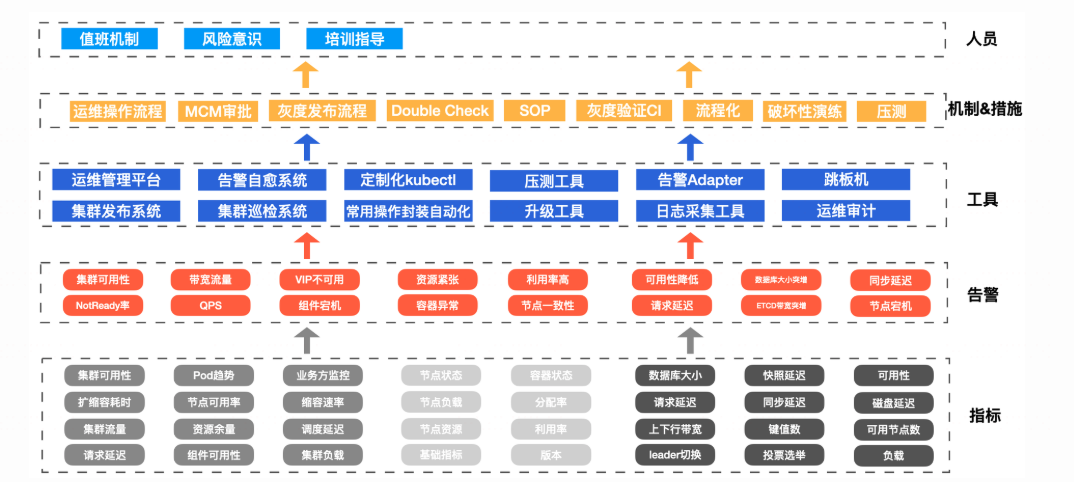
美团集群调度系统演变之路
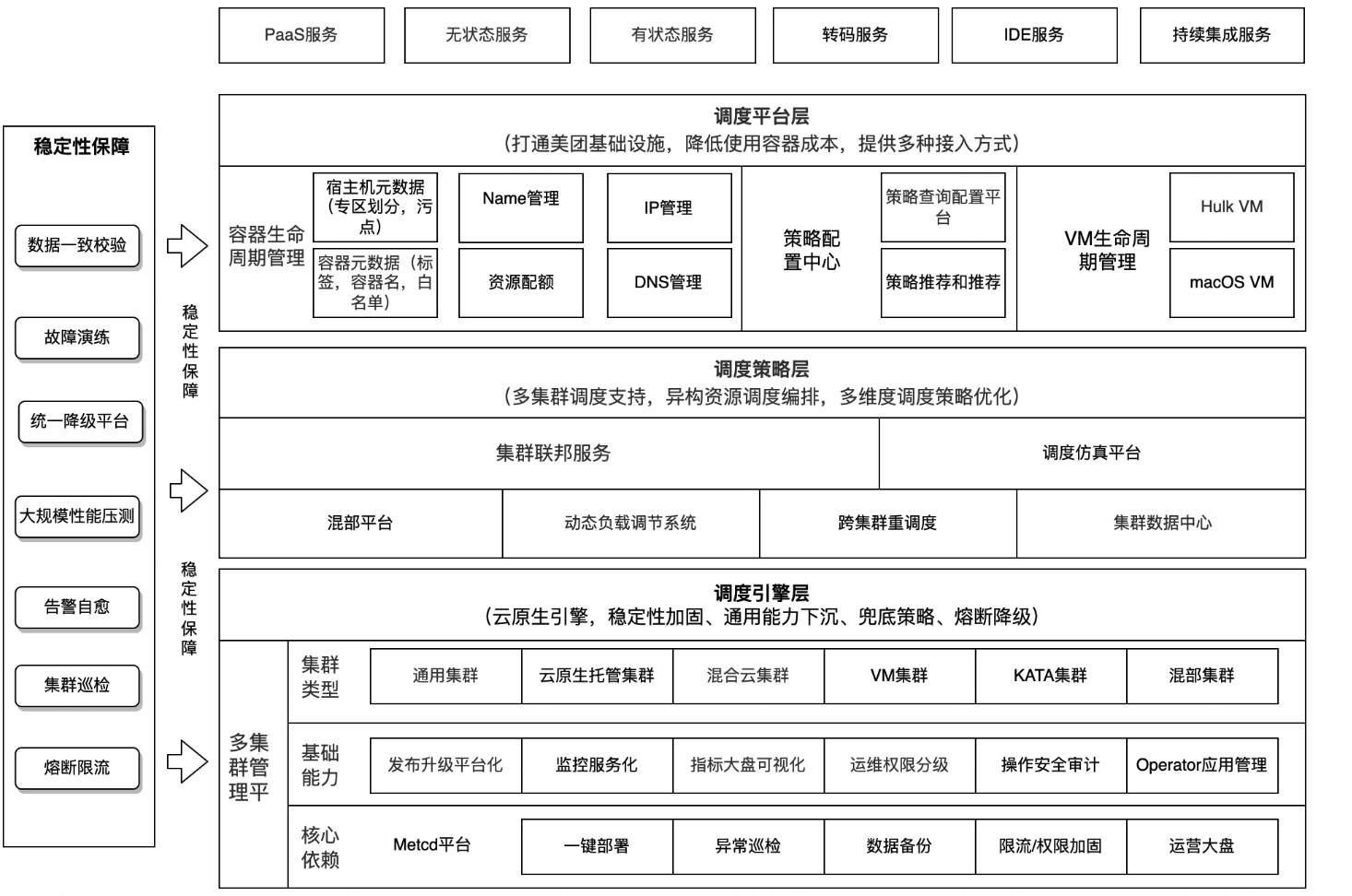
未来展望
已过时,美团现在已经全面容器化
- 统一调度:VM会少量长期存在一段时间,但如果同时维护两套基础设施产品成本是非常高的,所以我们也在落地Kubernetes来统一管理VM和容器。
- VPA:探索通过VPA来进一步提升整个资源的使用效率。
- 云原生应用管理:当前,我们已将云原生应用管理在生产环境落地,未来我们会进一步扩大云原生应用的覆盖面,不断提升研发效率。
- 云原生架构落地:推进各个中间件、存储系统、大数据以及搜索业务合作落地各个领域的云原生系统。
滴滴[5]
第一个阶段
2016 年,干了三个事情,容器编排引擎选型、 CI/CD 改造、监控平台配套升级。
在这个过程中,难就难在新老架构共存、兼顾用户使用习惯平滑过渡,我们在用户体验层面做了很多折中和优化,确保工程师们在使用的过程中不造反、不因为监控问题出现大故障,否则云原生之路就得戛然而止了。
在第一个阶段,一句话总结为:“平台起步,云原生技术选型和探索”。
第二个阶段
2017 年 H2,接入“有影响力的试点业务”。过程中,不出所料,出现了大大小小各种故障,也因为平台体验过于反人类、不稳定、性能有缺陷,加上用户习惯很难被快速扭转,被用户们吐槽的不轻。幸运的是,都跨过去了。
在第二个阶段,一句话总结为:“业务接入,驱动技术升级”。
第三个阶段
2019年开始,为了更充分发挥“云原生”的优势,开始落地在离线混部、推进中间件上云、全面搞服务治理、Auto-Scaling 能力开放、故障自动转移全面铺开等等,容器数量到达 10w。
总之,在这个阶段,反而是最平淡的一个阶段,所有的挑战都归结为技术问题。工程师们潜心钻研技术细节,研究各种奇技淫巧,死抠性能极限。
第三个阶段,一句话总结为:“在线业务全面接入,夯实云原生技术能力”。
第四个阶段
2021年,收获的阶段,线上线下、研发测试交付全流程打通,业务全面接入,基础设施对研发和业务方透明,在离线统一调度,容器数量达到数十万。
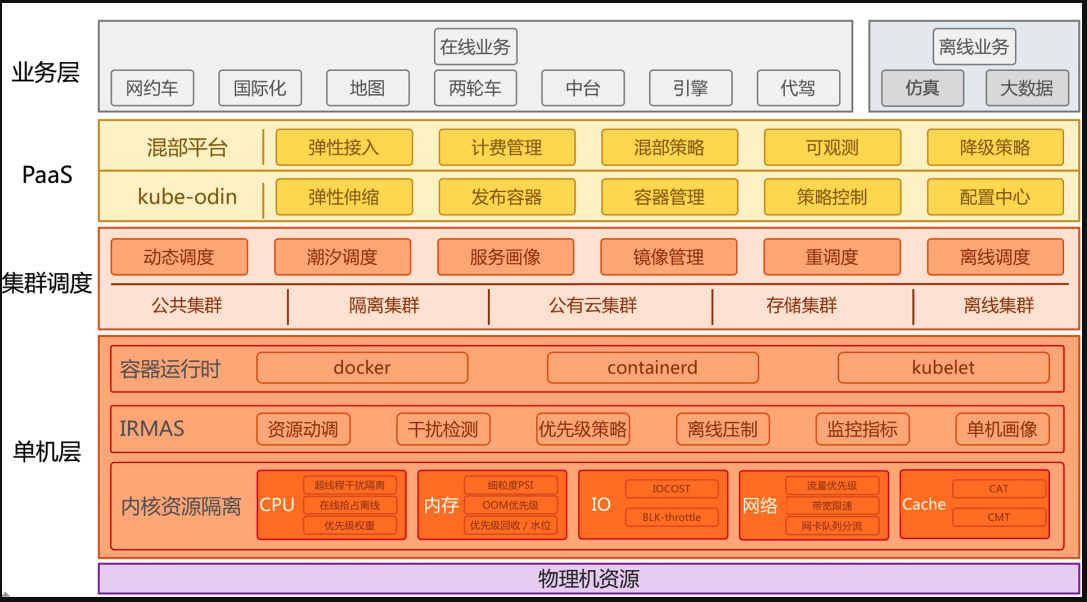
混部作为一种业界通用的降本的手段,充满着非常多的技术挑战,总结如下:
- 如何对业务进行合理的分级,不同级别的服务QoS如何定义
- 如何对业务进行精细化的画像,指导集群进行更合理的调度装箱,降低资源争抢的概率
- 单机如何进行内核层面的资源隔离策略,包括CPU、内存、IO、LLC cache、网络等资源,来保障高优业务的服务质量
- 单机如何进行性能干扰检测,指导单机驱逐和调度优化
vivo[6]
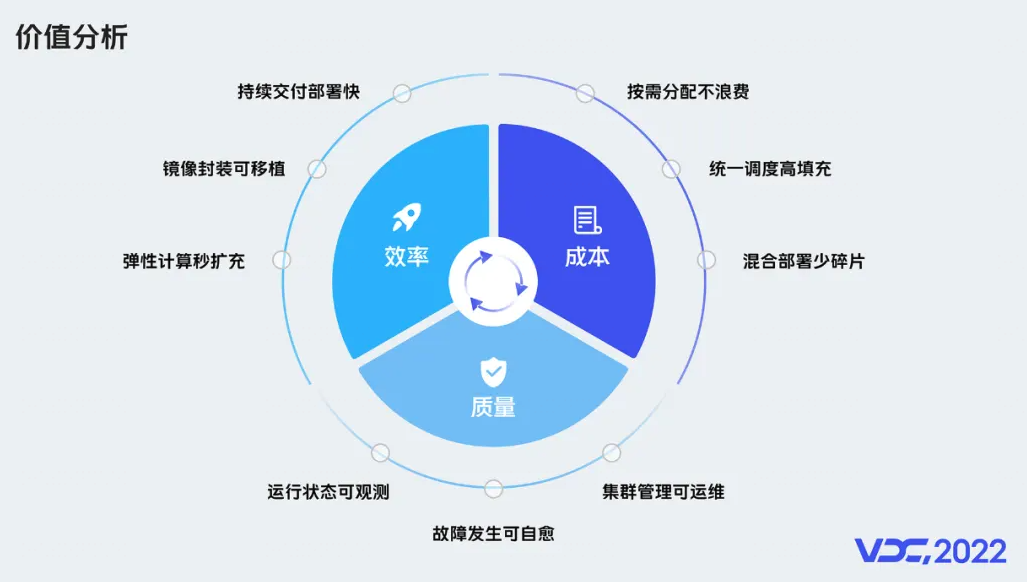
云原生价值分析
探索和挑战
试点探索:vivo云原生机器学习平台,成功为算法实现了降本、提效,让云原生和容器价值初露锋芒。
战略升级:为了更好匹配战略落地,拥抱云原生,我们还对内部技术架构重新规划和升级,新增引入统一流量接入平台、容器运维管理平台、统一名字服务、容器监控等平台和能力,支撑容器生态在公司内部的全面建设和推广。
集群挑战:集群规模快速增长、集群运维、运营和标准化、集群容器监控架构和可观测性、线上K8s版本升级迭代(需要实现给飞行的飞机换引擎)。
平台挑战:容器IP的变化、周边生态的适配和兼容、用户使用习惯、价值输出。
最佳实践
容器集群高可用建设
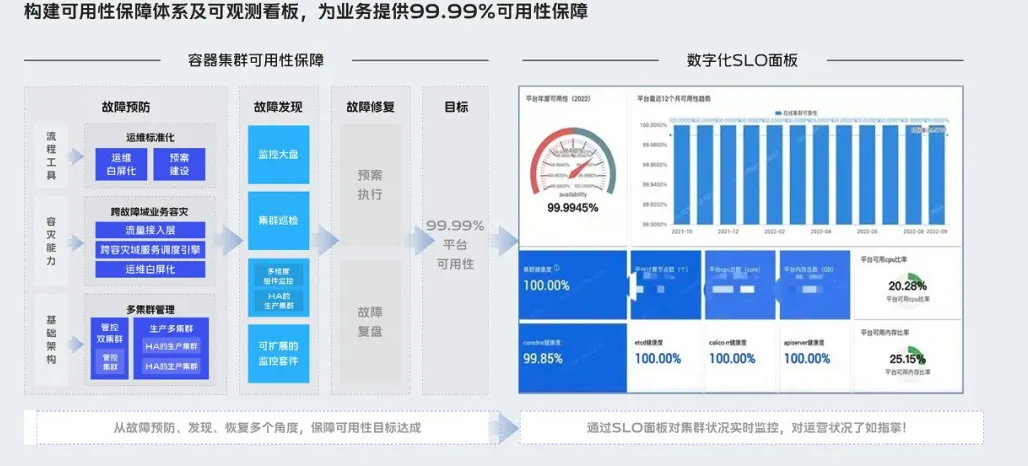
容器集群自动化运维
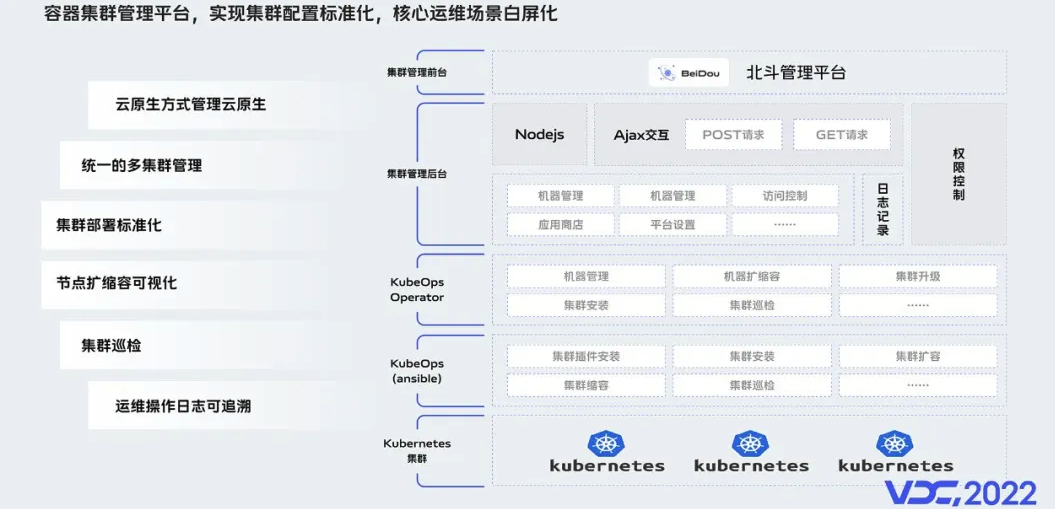
容器平台架构升级

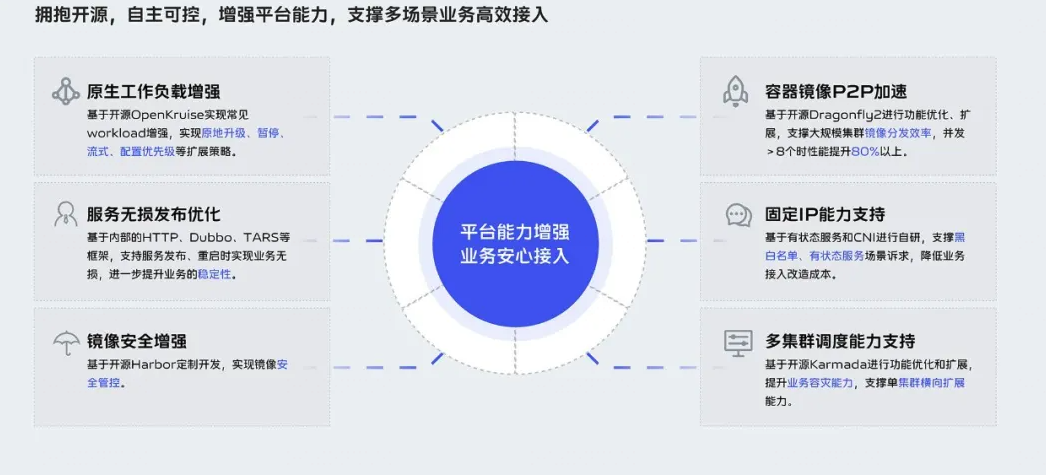
容器平台能力增强
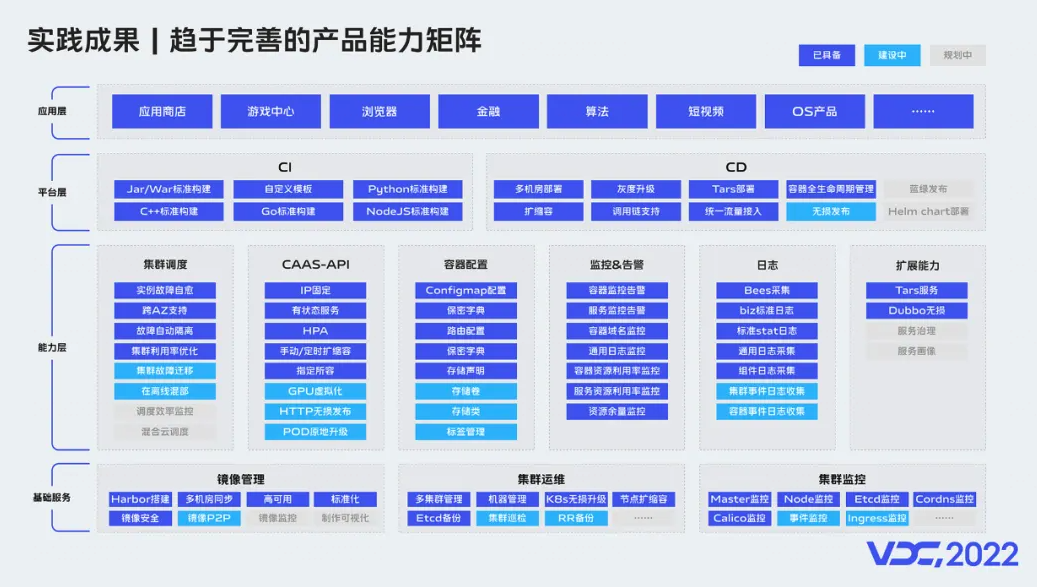
产品能力矩阵完善
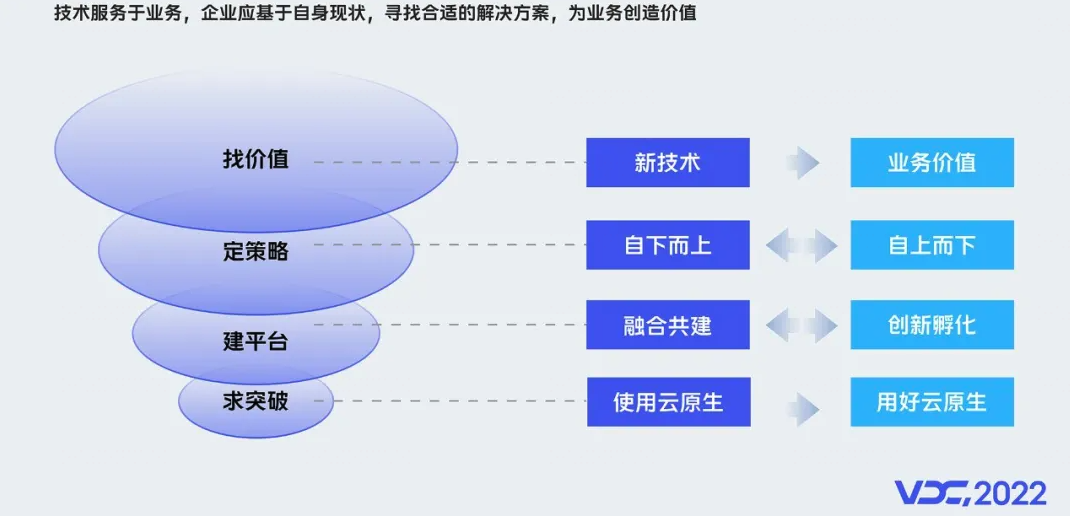
实践总结
对云原生的未来展望
PPT 汇总
美团容器平台降本运营落地实践
美团大规模容器集群降本增效实践
快手关键混部技术介绍
快手 CPU&GPU 超大规模在离线混部落地实践
快手 Kubernetes上的干扰检测和资源隔离增强的最佳实践
腾讯云原生降本增效最佳实践
腾讯如何管理超千万核资源的容器规模
小红书降本增效之路
小红书多集群打造面向混合云的高可用弹性架构
字节在 kubernetes 上构建一个精细化和智能化的资源管理系统
字节跳动云原生成本优化实践
字节如何将Kubernetes调度器的吞吐量提高数十倍
京东云跨集群大规模应用管理实践
网易云原生架构下中间件联邦高可用架构实践
vivo云原生容器探索和落地实践
vivo Kubernetes 集群无损升级实践
vivo服务端监控体系建设实践
阿里云云原生开放日
知乎在离线混部实践
PPT 下载地址:
链接: https://pan.baidu.com/s/1SHCZFvA-zKy7ptZI1jYitg 密码: 13qs
欢迎补充,交流学习~
期待你在留言区和我讨论,也欢迎把这篇文章分享给你的同事、朋友。让我们一起在实战中演练,在交流中进步。 ——倪朋飞
期待你在下面留言 企业落地云原生的最佳实践相关文章,共同学习~
以下每篇文章都值得仔细阅读。
参考资料:
[1] 云原生落地:https://clay-wangzhi.com/cloudnative/best-practice/containerization.html
云原生实践总结:https://clay-wangzhi.com/cloudnative/
[2] 涉及数万人、历时三年,国内最大规模的云原生实践是如何打造出来的?:https://www.infoq.cn/article/91e8yfsbe71oum3iolaf
[3] 从混合部署到融合调度:字节跳动容器调度技术演进之路:https://developer.volcengine.com/articles/7317093690483638281
字节跳动的云原生技术历程演进:https://developer.volcengine.com/articles/7317093834544906249
[4] Kubernetes如何改变美团的云基础设施?:https://tech.meituan.com/2020/08/13/openstack-to-kubernetes-in-meituan.html
美团集群调度系统的云原生实践 https://tech.meituan.com/2022/02/17/kubernetes-cloudnative-practices.html
[5] 万字详解滴滴弹性云混部的落地历程:https://mp.weixin.qq.com/s/jcjAZUHGcydEe9CcO_EDZQ
你们公司云原生转型持续了多长时间:https://mp.weixin.qq.com/s/k-2TVrY6oz_EZU8BhHgw1w
[6] vivo 云原生容器探索和落地实践:https://mp.weixin.qq.com/s/ux5z-EXmlN_2Qie6w9101g
我是 Clay,下期见 👋
欢迎订阅我的公众号「SRE运维进阶之路」或关注我的 Github https://github.com/clay-wangzhi/SreGuide 查看最新文章
欢迎加我微信
sre-k8s-ai,与我讨论云原生、稳定性相关内容
