
K8s CPU Throttle 优化方案
K8s CPU Throttle 优化方案
CPU Throttle 问题详解
受内核调度控制周期(cfs_period)影响,容器的 CPU 利用率往往具有一定的欺骗性,下图展示了某容器一段时间的 CPU 使用情况(单位为0.01核),可以看到在 1s 级别的粒度下(图中紫色折线),容器的 CPU 用量较为稳定,平均在 2.5 核左右。根据经验,管理员会将 CPU Limit设置为 4 核。本以为这已经保留了充足的弹性空间,然而若我们将观察粒度放大到 100ms 级别(图中绿色折线),容器的 CPU 用量呈现出了严重的毛刺现象,峰值达到 4 核以上。此时容器会产生频繁的 CPU Throttle,进而导致应用性能下降、RT 抖动,但我们从常用的 CPU 利用率指标中竟然完全无法发现!

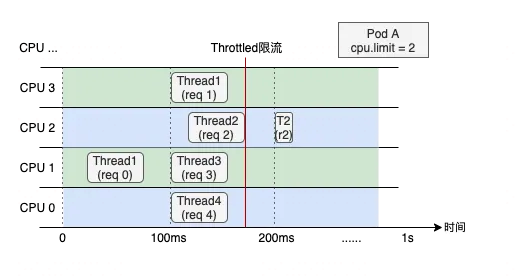
毛刺产生的原因通常是由于应用突发性的 CPU 资源需求(如代码逻辑热点、流量突增等),下面我们用一个具体的例子来描述 CPU Throttle 导致应用性能下降的过程。图中展示了一个CPU Limit = 2 的 Web 服务类容器,在收到请求后(req)各线程(Thread)的 CPU 资源分配情况。假设每个请求的处理时间均为 60 ms,可以看到,即使容器在最近整体的 CPU 利用率较低,由于在 100 ms~200 ms 区间内连续处理了4 个请求,将该内核调度周期内的时间片预算(200ms)全部消耗,Thread 2 需要等待下一个周期才能继续将 req 2 处理完成,该请求的响应时延(RT)就会变长。这种情况在应用负载上升时将更容易发生,导致其 RT 的长尾情况将会变得更为严重。
为了避免 CPU Throttle 的问题,我们只能将容器的 CPU Limit 值调大。然而,若想彻底解决 CPU Throttle,通常需要将 CPU Limit 调大两三倍,有时甚至五到十倍,问题才会得到明显缓解。而为了降低 CPU Limit 超卖过多的风险,还需降低容器的部署密度,进而导致整体资源成本上升。
调研 CPU Burst 方案
**什么是 CPU Burst:**CPU Burst(CPU 突发)是指在计算机处理器空闲时,允许进程或线程在一段短时间内使用超过其平均 CPU 使用量的额外 CPU 时间。在 CPU 突发期间,进程可以使用比其在限定时间段内被允许的平均 CPU 使用量更多的 CPU 资源,以提高应用程序的响应速度和性能。
方案对比
| koordinator + cpuBurstOnly | koordinator + cfsQuotaBurstOnly | 二开 koordlet 组件 + cfsQuotaBurstOnly | |
|---|---|---|---|
| 依赖 | 操作系统内核 >= 5.14 | ||
| 策略控制 | CRD/configmap/annotation | CRD/configmap/annotation | configmap/annotation |
| 功能&复杂度 | 功能强大且复杂 Koord-Scheduler/Koord-Descheduler/Koord-Manager/Koordlet/Koord-RuntimeProxy | 功能强大且复杂 Koord-Scheduler/Koord-Descheduler/Koord-Manager/Koordlet/Koord-RuntimeProxy | 功能单一简单,支持基于全局 cm 指定哪些 Pod 需要执行策略 Koordlet |
本项目的由来: 二开 koordlet 组件 + cfsQuotaBurstOnly 优化 K8s CPU Throttle 问题
项目架构

StatesInformer
- Node Informer:提供本节点 corev1.Node
- Pod Informer:提供本节点所有 PodMeta 信息, PodMeta 包括 corev1.Pod 和 CgroupDir
- PLEG:监听 Pod 变化,触发同步
- Kubelet:获取 GetAllPods
- CM Informer:提供全局 CM 指定哪些 Pod ,可以动态调节 cpu.cfs_quota_us
Metric Cache:Prometheus tsdb 存在收集到的指标
MetricCollectors
- Node Info:收集 Node CPU 核数等
- Node Resource:收集 Node CPU 、MEM 使用情况
- Pod Throttled:收集 Pod Throttled 信息,从 cpu.stat 收集
CPU Burst Plugin:发现 Pod Throttled, 动态调整 cpu.cfs_quota_us
快速开始
# 创建 ns
kubectl apply -f manifests/setup/
# 创建 rbac、cm、ds
kubectl apply -f manifests/
默认的 cm 内容如下:
其中 app:apache-demo 是用于匹配 Pod 的 label 的,匹配成功,则 Pod 应用 策略
cpu-burst-config 是默认的策略文件
apiVersion: v1
data:
app: apache-demo
cpu-burst-config: '{"policy": "cfsQuotaBurstOnly", "cpuBurstPercent": 100, "cfsQuotaBurstPercent":
300, "cfsQuotaBurstPeriodSeconds": -1}'
kind: ConfigMap
metadata:
name: cfs-quota-burst-cm
namespace: koordinator-system
创建 demo 测试
apiVersion: v1
kind: Pod
metadata:
name: apache-demo
labels:
app: apache-demo # use label enable or disable CPU Burst.
spec:
containers:
- command:
- httpd
- -D
- FOREGROUND
image: koordinatorsh/apache-2-4-51-for-slo-test:v0.1
imagePullPolicy: Always
name: apache
resources:
limits:
cpu: "4"
memory: 10Gi
requests:
cpu: "4"
memory: 10Gi
nodeName: # $nodeName Set the value to the name of the node that you use.
hostNetwork: False
restartPolicy: Never
schedulerName: default-scheduler
通过 wrk2 进行压力测试
./wrk -H "Accept-Encoding: deflate, gzip" -t 2 -c 12 -d 120 --latency --timeout 2s -R 24 http://$target_ip_address:8010/static/file.1m.test
将 demo 中 label 去掉,再进行测试
apiVersion: v1
kind: Pod
metadata:
name: apache-demo
spec:
containers:
- command:
- httpd
- -D
- FOREGROUND
image: koordinatorsh/apache-2-4-51-for-slo-test:v0.1
imagePullPolicy: Always
name: apache
resources:
limits:
cpu: "4"
memory: 10Gi
requests:
cpu: "4"
memory: 10Gi
nodeName: # $nodeName Set the value to the name of the node that you use.
hostNetwork: False
restartPolicy: Never
schedulerName: default-scheduler
kubectl delete pod apache-demo
kubectl apply -f apache-demo.yaml
测试结果如下:
| 默认 | 开启 cfsQuotaBurstOnly | |
|---|---|---|
| apache RT-p99 | 231.93ms | 99.52ms |
Show me Code
源码地址:https://github.com/clay-wangzhi/cfs-quota-burst
参考链接:
如何合理使用 CPU 管理策略,提升容器性能?:https://developer.aliyun.com/article/872282
Koordinator cpuBurst: https://koordinator.sh/zh-Hans/docs/user-manuals/cpu-burst
我是 Clay,下期见 👋
欢迎订阅我的公众号「SRE运维进阶之路」或关注我的 Github https://github.com/clay-wangzhi/SreGuide 查看最新文章
欢迎加我微信
sre-k8s-ai,与我讨论云原生、稳定性相关内容
