
什么?相同型号物理机 容器性能不如虚拟机?
什么?相同型号物理机 容器性能不如虚拟机?
事件经过
该应用通过虚拟机和容器混合部署,上线前压测了虚拟机上的应用性能,理论上流量高峰能抗住。
[xx:xx] 流量突增,接口大量超时
[xx:xx] 限流
[xx:xx] 重启,虚拟机能重启成功,容器重启失败,容器流量摘除,暂时恢复
[xx:xx] 扩容, 容器虚拟机均扩容
[xx:xx] 两台容器异常,流量摘除
[xx:xx] 一段时间后观察正常,解除限流
[xx:xx] 流量比上一次还大,接口大量超时
[xx:xx] 限流
[xx:xx] 扩容,扩容发布均有失败,但是虚拟机成功率高,容器 fullGC 时间长,请求堆积,异常
[xx:xx] 定位代码存在性能问题
[xx:xx] 修复代码 bug,解决问题
[xx:xx] 定位到容器性能与虚拟机有一定差距(TPS 差一倍,平均 RT 高)
[xx:xx] 解决容器性能问题
根因分析
代码有 Bug , 启动都会 fullGC ,都有启动失败的概率,但是容器 fullGC 耗时长,请求会不断堆积, 而虚拟机过段时间可以自行恢复
这里主要定位,为什么容器 fullGC 时间长,以及容器 TPS 低,平均 RT 高的问题
定位分析业务的性能问题,也是很多程序员都很头疼的问题。需要你具备很高的业务能力,包括对业务流程的熟悉度、对软件架构及软件内实现逻辑的理解程度,甚至是对OS和硬件原理都要有深入的理解。即使是掌握了这些信息,如果没有系统的定位分析方法的指导,那你依旧很难定位出性能问题。

如上图: 排除 业务层 和 软件架构 两层,相同代码,相同物理机型号,相同机房的情况下,现在需要识别 软硬件性能瓶颈。
ok,热烈欢迎 性能领域的大师布伦丹·格雷格(Brendan Gregg)登场 👏👏👏
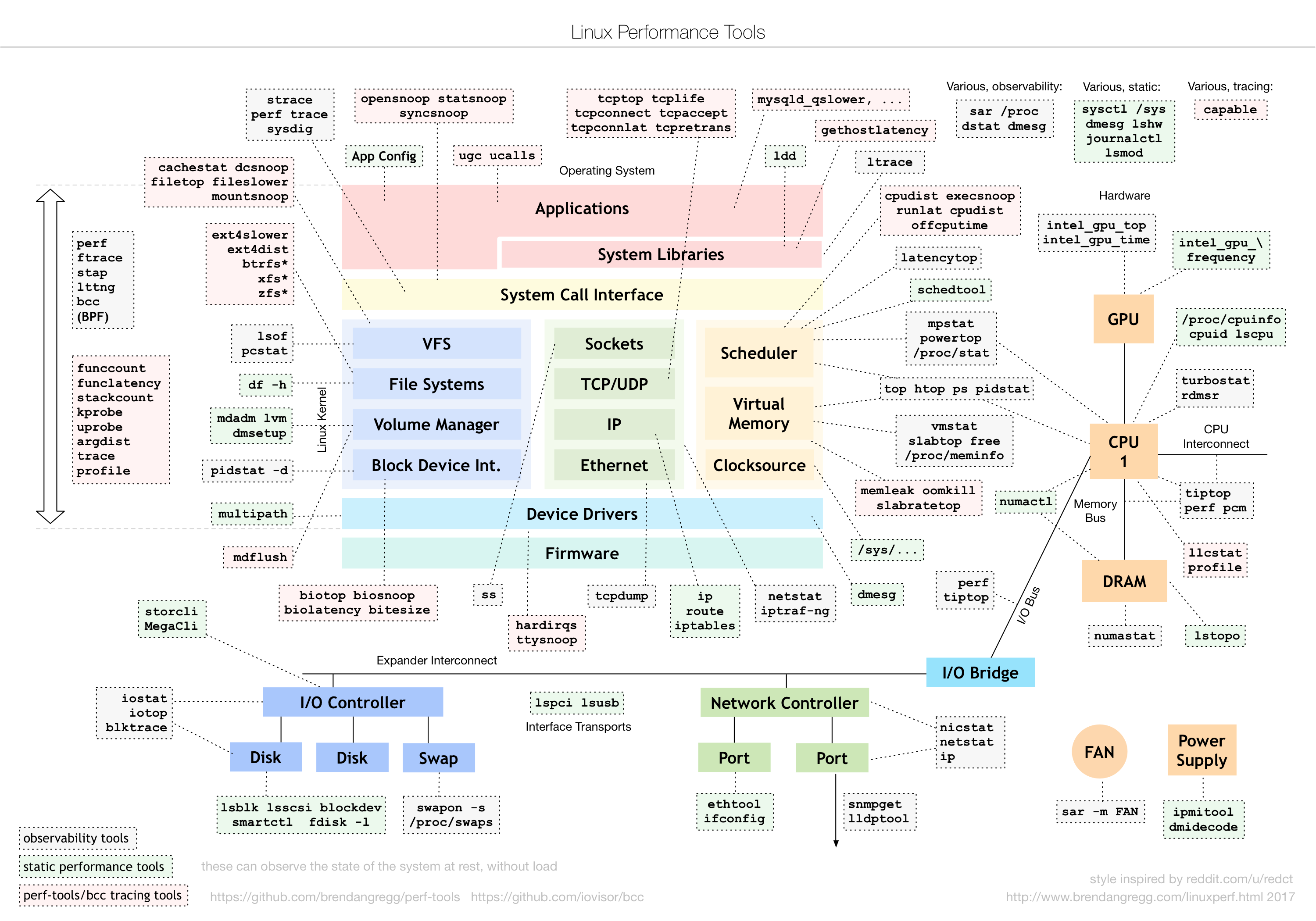
利用 随机变动讹方法(猜测,改动,观察验证) 查问题
# 先看 CPU,观察 CPU MHz、CPU max MHz、CPU min MHz,发现CPU MHz 处于 min 值
lscpu
# 查看当前 CPU 性能模式
cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor
# 调整设置为 performance 模式,进行验证
cpupower frequency-set -g performance
Nice,定位到了根因 ✌️
后续 TODO
1)补全监控告警
将 node_exporter 升级到 1.6.0
- [ENHANCEMENT] Add cpu frequency governor metrics #2569
添加告警规则
name: CPU 性能模式非 performance
expr: (sum by(instance) (node_cpu_scaling_governor{governor!="performance"}) > 0)
2)将虚拟机和容器, 进行 基础性能压测和服务性能压测,形成对比压测报告
调整 CPU 性能模式后, 容器的整体性能 好于 虚拟机,主要体现在 磁盘性能方面,容器更优
规格均为:4c8g, 相同型号物理机
| 虚拟机 | 容器 | |||
|---|---|---|---|---|
| 基础性能 | ||||
| 计算性能 | Super_Pi | 21.244秒 | 20.915秒 | ~= |
| CPU调度延时 单线程 | 56.7微秒 | 16.7微秒 | ↑ | |
| CPU调度延时 2线程 | 58.7微秒 | 19.3微秒 | ↑ | |
| CPU调度延时 4线程 | 66.3微秒 | 26.3微秒 | ↑ | |
| sysbench 素数计算 单线程 | 4.483秒 | 4.454秒 | ~= | |
| sysbench 素数计算 2线程 | 2.244秒 | 2.227秒 | ~= | |
| sysbench 素数计算 4线程 | 1.124秒 | 1.116秒 | ~= | |
| 内存性能 | 内存带宽(stream) 单线程 | Copy:11.0GB/s | Copy:12.9GB/s | ~= |
| 内存带宽(stream) 单线程 | Scale:11.1GB/s | Scale:13.0GB/s | ~= | |
| 内存带宽(stream) 单线程 | Add:12.5GB/s | Add:14.4GB/s | ~= | |
| 内存带宽(stream) 单线程 | Triad:12.7GB/s | Triad:14.6GB/s | ~= | |
| 内存时延(mlc) | 138.0纳秒 | 146.8纳秒 | ~= | |
| sysbench 顺序写 | 4082.59MiB/sec | 4657.52MiB/sec | ~= | |
| sysbench 顺序读 | 52616.00MiB/sec | 74925.36MiB/sec | ↑ | |
| sysbench 随机写 | 527.66MiB/sec | 533.09MiB/sec | ||
| sysbench 随机读 | 7485.14MiB/sec | 8376.67MiB/sec | ↑ | |
| 文件I/O性能 | sysbench 随机读 IOPS | 2759.53 | 14136.79 | ↑ |
| sysbench 随机写 IOPS | 1839.72 | 9424.53 | ↑ | |
| sysbench 顺序写吞吐量 | 76.89 MiB/s | 1726.56 MiB/s | ↑ | |
| sysbench 顺序读吞吐量 | 17560.41 MiB/s | 12356.24 MiB/s | ↓ | |
| dd 顺序写 | 125.3 MB/s | 1262.9 MB/s | ↑ | |
| 网络性能 | 传输速率(pps) | 60w/s | 49w/s | ↓ |
| 网络带宽 | 8.75Gbps | 8.75Gbps | ~= | |
| 单向时延 | 104.274微妙 | 30.743微秒 | ~= | |
| ping 时延 | 0.143毫秒 | 0.102毫秒 | ~= | |
| 应用性能 | ||||
| Nginx | 短连接 QPS | 2.92万 | 3.20万 | ~= |
| 长连接 QPS | 17.75万 | 14.13万 | ↓ | |
| MySQL | 读 | 79.19万/300秒 | 651.29万/300秒 | ↑ |
| 写 | 22.63万/300秒 | 186.08万/300秒 | ↑ | |
| Redis | Set | 14.88万/秒 | 15.42万/秒 | ↑ |
| Get | 15.22万/秒 | 14.74万/秒 | ↓ |
同类硬件问题总结
CPU
CPU-动态节能技术
cpufreq 是一个动态调整 CPU 频率的模块,可支持五种模式。为保证服务性能应选用 performance 模式,将 CPU 频率固定工作在其支持的最高运行频率上,从而获取最佳的性能,一般都是默认 powersave,可以通过 cpupower frequency-set 修改。
# 查看当前 CPU 性能模式
cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor
# 查看当前 CPU 使用频率
cat /proc/cpuinfo | grep -i "cpu mhz"
# 综合查看方式
cpupower frequency-info
# 设置为 performance 模式
cpupower frequency-set -g performance
# 注意:如果使用 cpupower frequency-set 设置后,重启物理机后,配置失败,可能是 tuned-adm 的原因
# 所以建议使用 tuned-adm 设置 CPU 性能模式
tuned-adm profile latency-performance
RAID 卡
写入策略对顺序写入性能影响比较大
Write Policy(写入策略):Write Through(透写):并不利用 Raid 卡的 Cache,直接与磁盘进行交互。Write Back(回写):是先写 Raid 卡缓存,再传入磁盘。因为写入缓存,操作系统就认为成功了,所以测试会发现写入性能非常快。 推荐
Read Policy(读取策略):Read-ahead(预读,适合顺序读)No-Read-Ahead(Normal非预读,一般在 Windows 服务器下推荐)
开启预读对顺序读影响很大测试会差20%-40%性能。
Tips 在《MySQL 技术内幕-InnoDB存储引擎》 第二版第9章,性能调优部分。有关于
Write Policy的介绍,根据作者实测 MySQL,Write Back比Write Through快将近 40 倍差距。
# 查看 RAID 卡当前读写策略,去带外管理台看会方便一些
# 去官网 Broadcom 下载 rpm 包,到服务器上去安装
rpm -ivh storcli-007.2508.0000.0000-1.noarch.rpm
# 写入策略改为 WB
## v0 是查询结果,不同型号 name 不同
cd /opt/MegaRAID/storcli/ && ./storcli64 /c0 /v0 set wrcache=WB
# 读取策略改为 RA
cd /opt/MegaRAID/storcli/ && ./storcli64 /c0 /v0 set rdcache=ra
经验教训
上线前,基准测试的重要性 & 基准测试要包含应用的,以应用感知为准。
下篇会详细 服务器性能压测指标及方法。
参考链接:性能优化高手课 | 尉刚强
我是 Clay,下期见 👋
欢迎订阅我的公众号「SRE运维进阶之路」或关注我的 Github https://github.com/clay-wangzhi/wiki 查看最新文章
欢迎加我微信
sre-k8s-ai,与我讨论云原生、稳定性相关内容
