
K8s 无备份,不运维
K8s 无备份,不运维
出故障时,就知道是谁在裸泳 🙃
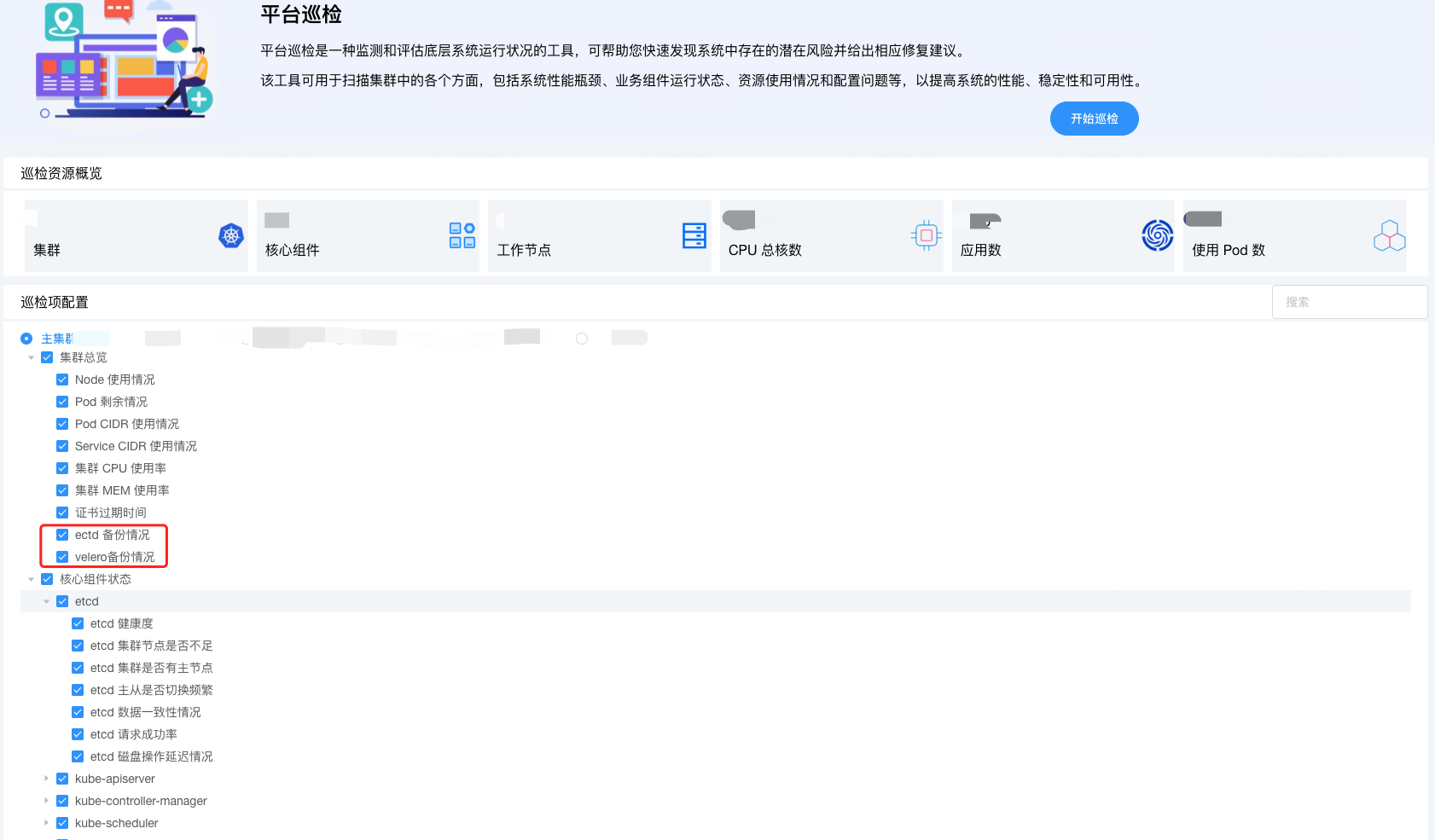
K8s 投产使用,备份是保命手段,必须要上,建议做一个 checklist,巡检通过,集群才能对外提供服务,比如,这样👇
备份方案制定
- 物理备份:etcd 备份,保存某一个时刻的快照,快捷方便。
- 逻辑备份:velero 备份 ,允许用户自己选择备份的内容,比如单个 namespace、指定资源类型等。
物理备份的优点是速度快,无论是备份还是回恢复,但缺点是元数据不可读,只能全部恢复。而逻辑备份正好相反,因此两者可以结合使用,既能快,又能有细粒度控制的能力。
Etcd 备份
1、创建备份脚本/opt/etcd_backup.sh
#!/usr/bin/env bash
#
# Etcd backup
set -e
ETCD_CA_CERT="/etc/kubernetes/pki/etcd/ca.crt"
ETCD_CERT="/etc/kubernetes/pki/etcd/server.crt"
ETCD_KEY="/etc/kubernetes/pki/etcd/server.key"
BACKUP_DIR="/var/lib/docker/etcd_backup"
DT=$(date +%Y%m%d.%H%M%S)
[[ ! -d ${BACKUP_DIR} ]] && mkdir -p ${BACKUP_DIR}
find ${BACKUP_DIR} -name "*.db" -mtime +7 -exec rm -f {} \;
ETCDCTL_API=3 /usr/local/bin/etcdctl --endpoints=https://127.0.0.1:2379 \
--cacert="${ETCD_CA_CERT}" --cert="${ETCD_CERT}" --key="${ETCD_KEY}" \
snapshot save "${BACKUP_DIR}/etcd-snapshot-${DT}.db"
echo "Etcd backup success, backup file: ${BACKUP_DIR}/etcd-snapshot-${DT}.db, \
file size: $(du -sh ${BACKUP_DIR}/etcd-snapshot-${DT}.db |awk '{print $1}')"
echo
2、添加cron定时任务 crontab -e
只需要备份一个etcd就行,恢复时,拿同一份备份数据恢复
0 */1 * * * /bin/bash /opt/etcd_backup.sh >>/opt/log-backup-etcd.log 2>&1
velero 备份
1、安装配置 velero
# 下载版本:https://github.com/vmware-tanzu/velero/releases 最新稳定版,注意k8s版本兼容性,1.8.1版本要求k8s版本至少1.16
wget https://github.com/vmware-tanzu/velero/releases/download/v1.8.1/velero-v1.8.1-linux-amd64.tar.gz
# 解压
tar -xvf velero-v1.8.1-linux-amd64.tar.gz
# 加入环境变量
cp velero-v1.8.1-linux-amd64/velero /usr/bin/
# 设置补全命令
velero completion bash > /etc/bash_completion.d/velero.sh
source /etc/bash_completion.d/velero.sh
# 创建凭证文件 cat credentials-velero
aws_access_key_id=xxx
aws_secret_access_key=xxx
# 安装
velero install --provider aws --plugins velero/velero-plugin-for-aws:v1.1.0 --bucket velero-xxx --secret-file ./credentials-velero --use-volume-snapshots=false --use-restic --default-volumes-to-restic --backup-location-config region=ap-shanghai,s3ForcePathStyle="true",s3Url=https://cos.ap-shanghai.myqcloud.com --restic-pod-cpu-request=1000m --restic-pod-cpu-limit=2000m --restic-pod-mem-request=1024Mi --restic-pod-mem-limit=4096Mi --velero-pod-cpu-request=1000m --velero-pod-cpu-limit=2000m --velero-pod-mem-request=1024Mi --velero-pod-mem-limit=4096Mi
# 查看配置的存储位置是否可用
velero backup-location get
2、根据实际情况备份指定 namespace 或 指定资源类型
velero create schedule xxx --schedule="0 1 * * *" --include-namespaces=prod --snapshot-volumes=false --default-volumes-to-restic=false --ttl=168h
Etcd 恢复
1、创建备份目录
mkdir -p /opt/k8s_manifests_backup
2、停止所有 Master 上 kube-apiserver 服务
mv /etc/kubernetes/manifests/kube-apiserver.yaml /opt/k8s_manifests_backup/
# 检查服务是否已停止
kubectl get pod -n kube-system | grep kube-apiserver
3、停止集群中所有 etcd 服务
# 记录 etcd --name、--initial-advertise-peer-urls、--data-dir 值
ps -ef | grep etcd
# 停止服务
mv /etc/kubernetes/manifests/etcd.yaml /opt/k8s_manifests_backup/
# 检查服务是否已停止
docker ps | grep etcd
4、移除所有 etcd 存储目录下数据,不同环境下,存储目录可能不一样,样例存储目录为 /data/etcd
mv /data/etcd{,.bak}
5、拷贝要恢复的快照到所有 etcd 节点,进行快照恢复 所有 etcd 节点操作,不同节点,传入不同的 --name、--initial-advertise-peer-urls、--data-dir值
ETCDCTL_API=3 /usr/local/bin/etcdctl snapshot restore /tmp/xxx.db \
--name hostname1 \
--initial-cluster "hostname1=https://ip1:2380,hostname2=https://ip2:2380,hostname3=https://ip3:2380" \
--initial-cluster-token k8s_etcd \
--initial-advertise-peer-urls https://ip1:2380 \
--data-dir=/data/etcd
6、启动集群中所有 etcd
mv /opt/k8s_manifests_backup/etcd.yaml /etc/kubernetes/manifests/
# 检查集群状态
ETCDCTL_API=3 /usr/local/bin/etcdctl --cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
--endpoints=https://ip1:2379,https://ip2:2379,https://ip3:2379 \
endpoint health
7、启动所有 Master 上 kube-apiserver 服务
mv /opt/k8s_manifests_backup/kube-apiserver.yaml /etc/kubernetes/manifests/
# 检查服务状态
kubectl get pod -n kube-system | grep kube-apiserver
8、检查是否如期恢复
总结
Kubernetes 集群备份主要是备份etcd集群。而恢复时,主要考虑恢复整个顺序:
停止Kube-apiserver --> 停止etcd --> 恢复数据 --> 启动etcd --> 启动kube-apiserver
velero 恢复
# 查询备份信息
velero backup get
# 按需下载备份文件
velero backup download filename
# 解压
tar -xvf xxx.tar.gz
# 根据需要进行 yaml 文件恢复
kubectl apply -f filename/dirname
上线前,除了要做好必要的备份外,还有做好 容量规划、网络规划、架构规划、组件基准测试等,后续继续分享~
我是 Clay,下期见 👋
欢迎订阅我的公众号「SRE运维进阶之路」或关注我的 Github https://github.com/clay-wangzhi/wiki 查看最新文章
欢迎加我微信
sre-k8s-ai,与我讨论云原生、稳定性相关内容
