
Etcd 概述及运维实践

Etcd 概述
什么是 Etcd ?
Etcd 是 CoreOS 团队于2013年6月发起的开源项目,它的目标是构建一个高可用的分布式键值(key-value)数据库。etcd内部采用raft协议作为一致性算法,Etcd基于 Go 语言实现。
名字由来,它源于两个方面,unix的“/etc”文件夹和分布式系统(“D”istribute system)的D,组合在一起表示etcd是用于存储分布式配置的信息存储服务。
原创大约 12 分钟
Etcd 是 CoreOS 团队于2013年6月发起的开源项目,它的目标是构建一个高可用的分布式键值(key-value)数据库。etcd内部采用raft协议作为一致性算法,Etcd基于 Go 语言实现。
名字由来,它源于两个方面,unix的“/etc”文件夹和分布式系统(“D”istribute system)的D,组合在一起表示etcd是用于存储分布式配置的信息存储服务。
etcd默认的空间配额限制为2G,超出空间配额限制就会影响服务,所以需要定期清理
设置环境变量
ETCD_CA_CERT="/etc/kubernetes/pki/etcd/ca.crt"
ETCD_CERT="/etc/kubernetes/pki/etcd/server.crt"
ETCD_KEY="/etc/kubernetes/pki/etcd/server.key"
HOST_1=https://xxx.xxx.xxx.xxx:2379
本次演练旨在测试 Kubernetes 的 etcd 高可用性,检验是否能够在其中一个 etcd 节点发生故障的情况下,其他 etcd 节点能够接管其工作,确保集群仍能正常运行。
集群架构
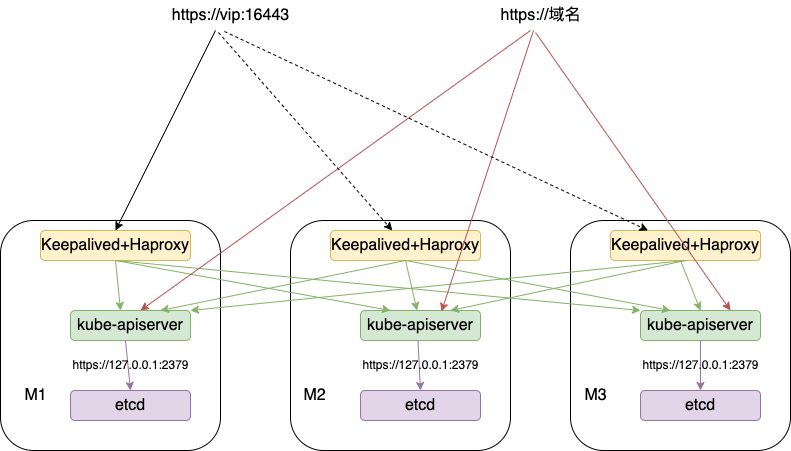
在一个三节点的 Kubernetes 集群中,我们将模拟其中一个 etcd 节点的故障,观察剩余的 etcd 节点是否能够正常运行。