
云原生思维导图
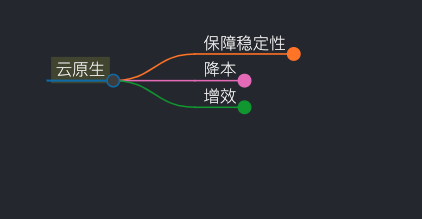
从保稳、降本、增效三个方向出发
稳定性就是不出故障,围绕着故障周期,进行梳理。
事前--->事中--->事后
降发生:事前/事后,将异常风险左移
降发生事前:高可用、持续风险治理、持续巡检、持续故障演练(演练库、预案库)、全链路压测、支持灰度发布和快速回滚
小于 1 分钟
从保稳、降本、增效三个方向出发
稳定性就是不出故障,围绕着故障周期,进行梳理。
事前--->事中--->事后
降发生:事前/事后,将异常风险左移
降发生事前:高可用、持续风险治理、持续巡检、持续故障演练(演练库、预案库)、全链路压测、支持灰度发布和快速回滚
Clay、腾讯、字节、美团、滴滴、Vivo等各大公司云原生落地实践 整理汇总
一句话概括:在保证稳定性的前提下,降本增效
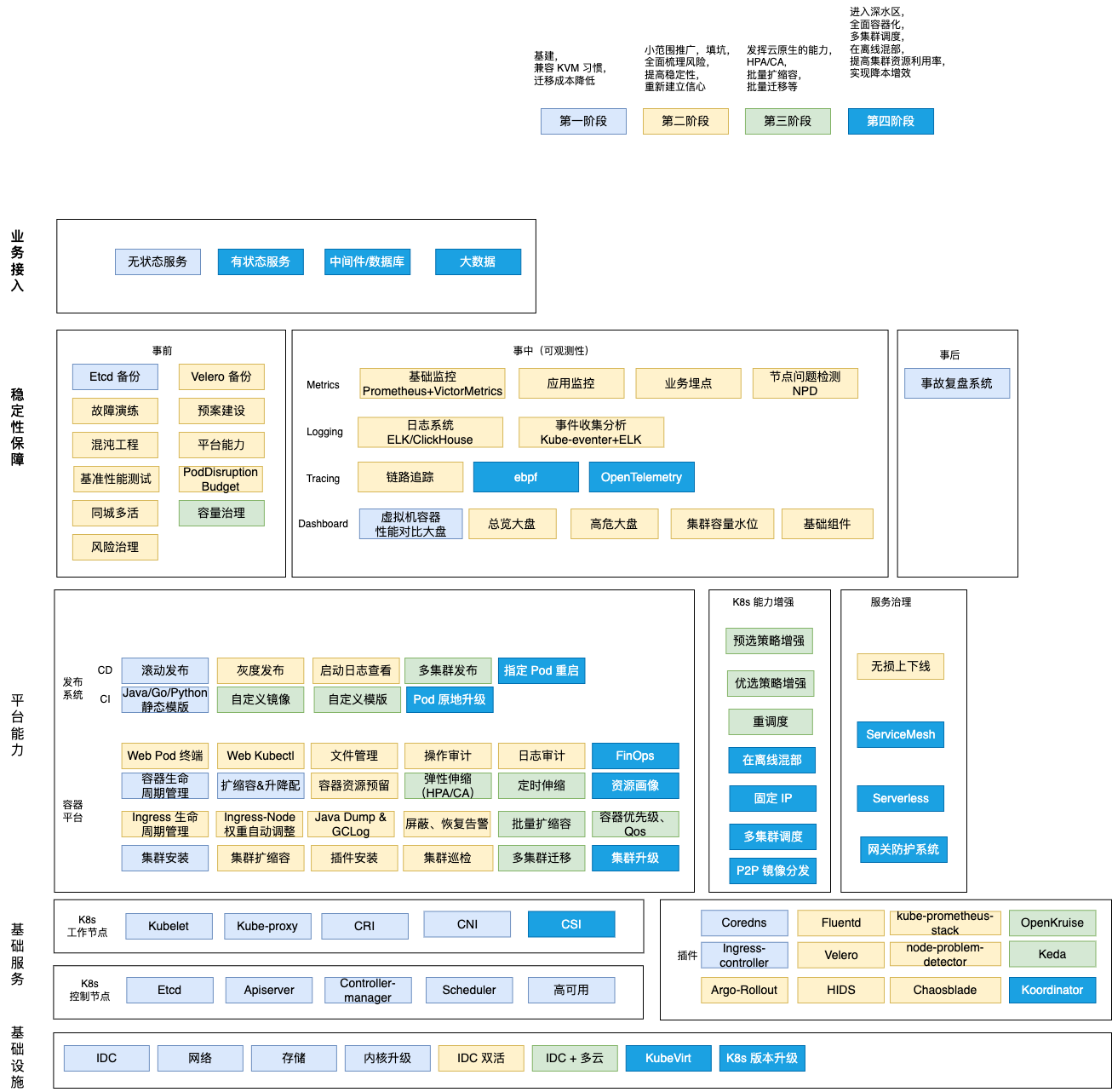
1)项目立项,确定目标,从上到下,从下到上,一同发力。
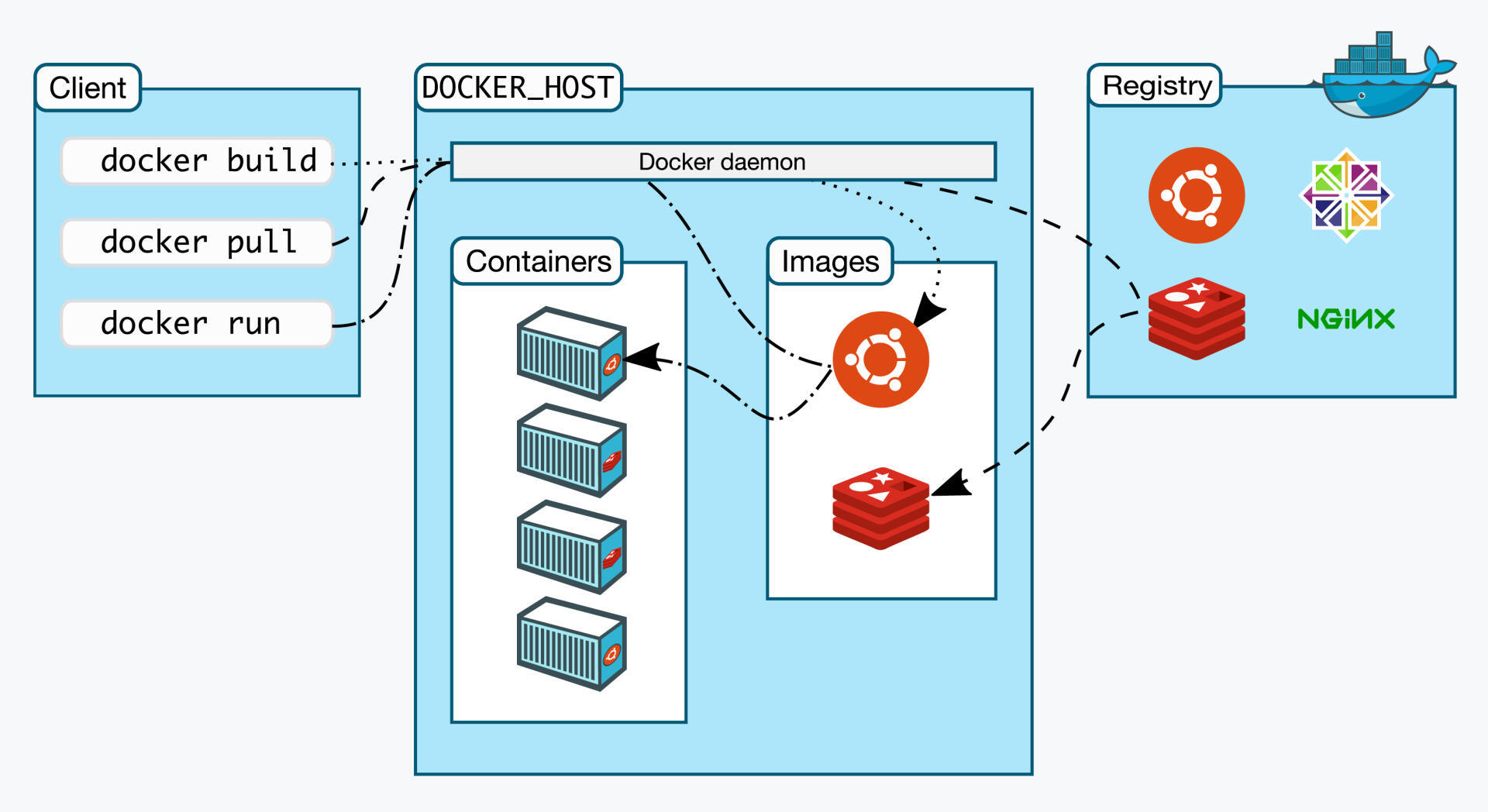
Docker 使用 C/S (客户端/服务器)体系的架构,Docker 客户端与 Docker 守护进程(Dockerd)通信,Docker 守护进程负责构建,运行和分发 Docker 容器。Docker 客户端和守护进程可以在同一个系统上运行,也可以将 Docker 客户端连接到远程 Docker 守护进程。Docker 客户端和守护进程使用 REST API 通过 UNIX 套接字或网络接口进行通信。
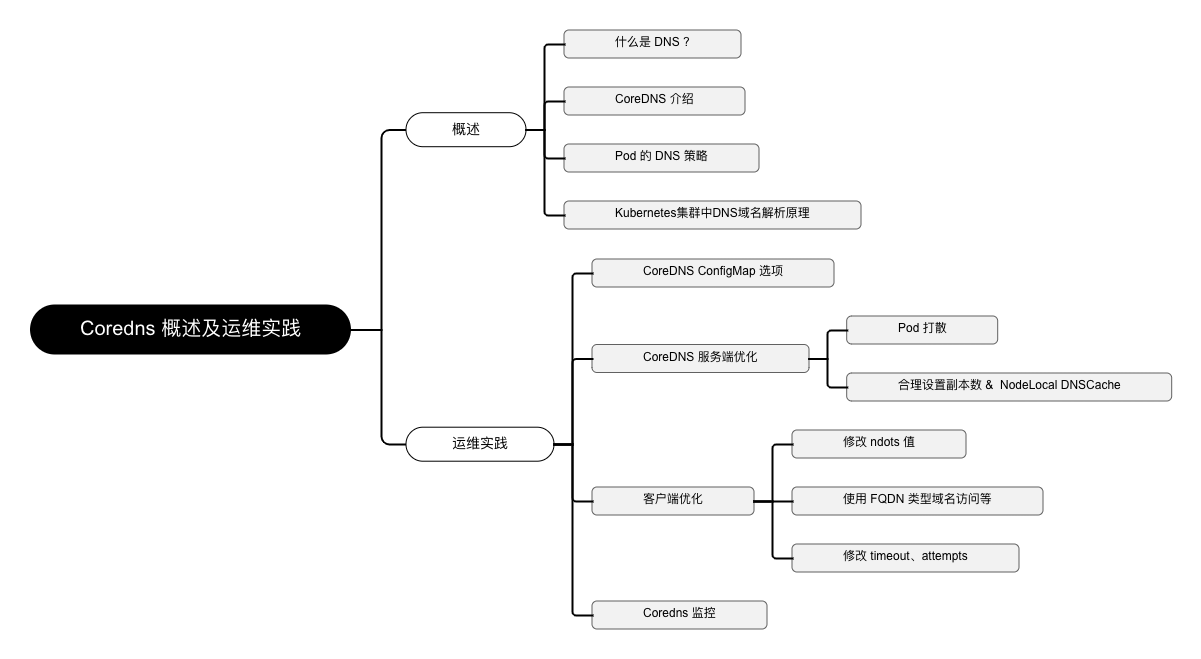
域名系统(英语:Domain Name System,缩写:DNS)是互联网的一项服务。它作为将域名和IP地址相互映射的一个分布式数据库,能够使人更方便地访问互联网。DNS使用TCP和UDP端口53。
Etcd 是 CoreOS 团队于2013年6月发起的开源项目,它的目标是构建一个高可用的分布式键值(key-value)数据库。etcd内部采用raft协议作为一致性算法,Etcd基于 Go 语言实现。
名字由来,它源于两个方面,unix的“/etc”文件夹和分布式系统(“D”istribute system)的D,组合在一起表示etcd是用于存储分布式配置的信息存储服务。
本文目录:
顾名思义:负责将 Pod 调度到 Node 上。

容器编排、调度平台,是一个完备的分布式系统支撑平台。
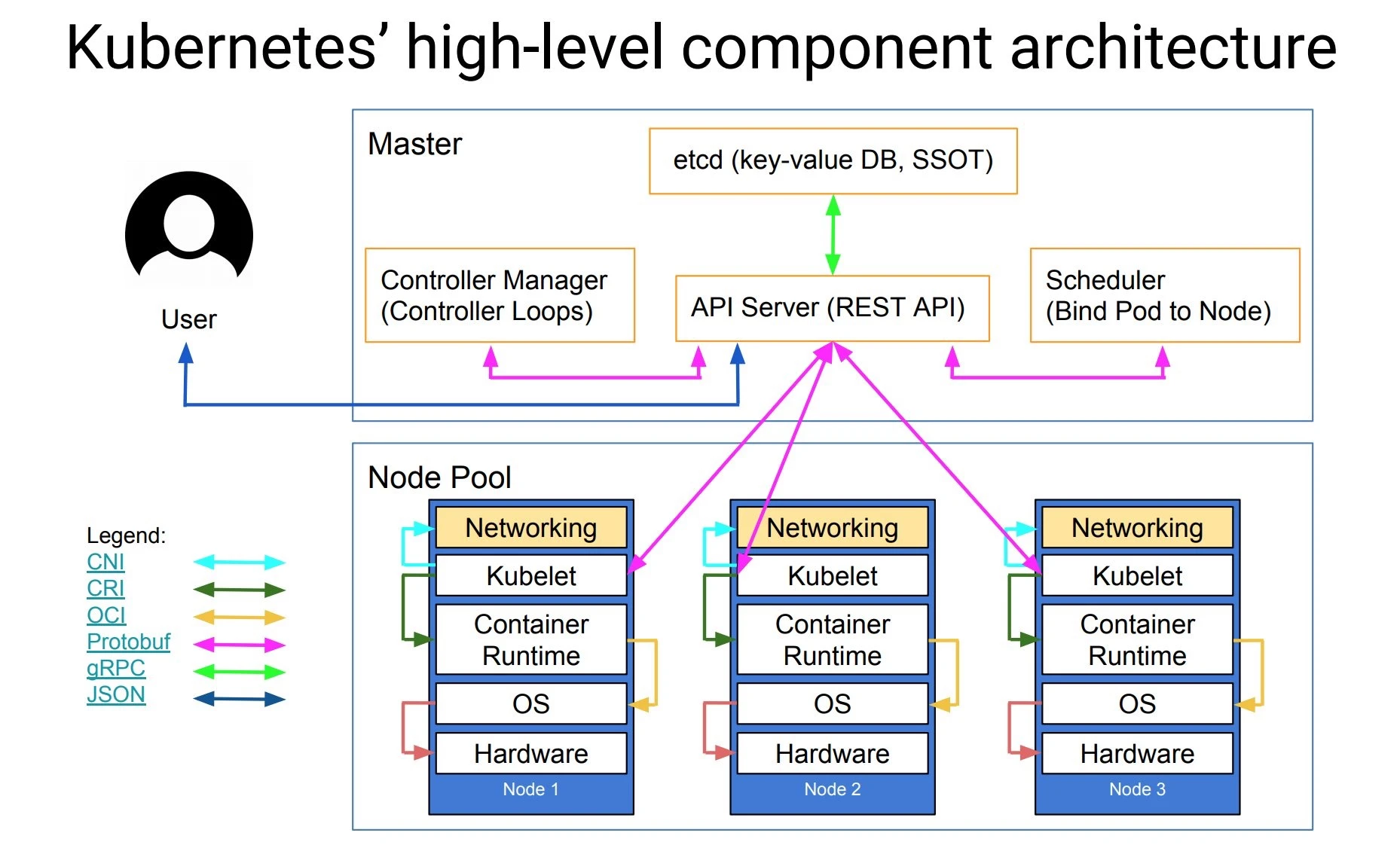
架构
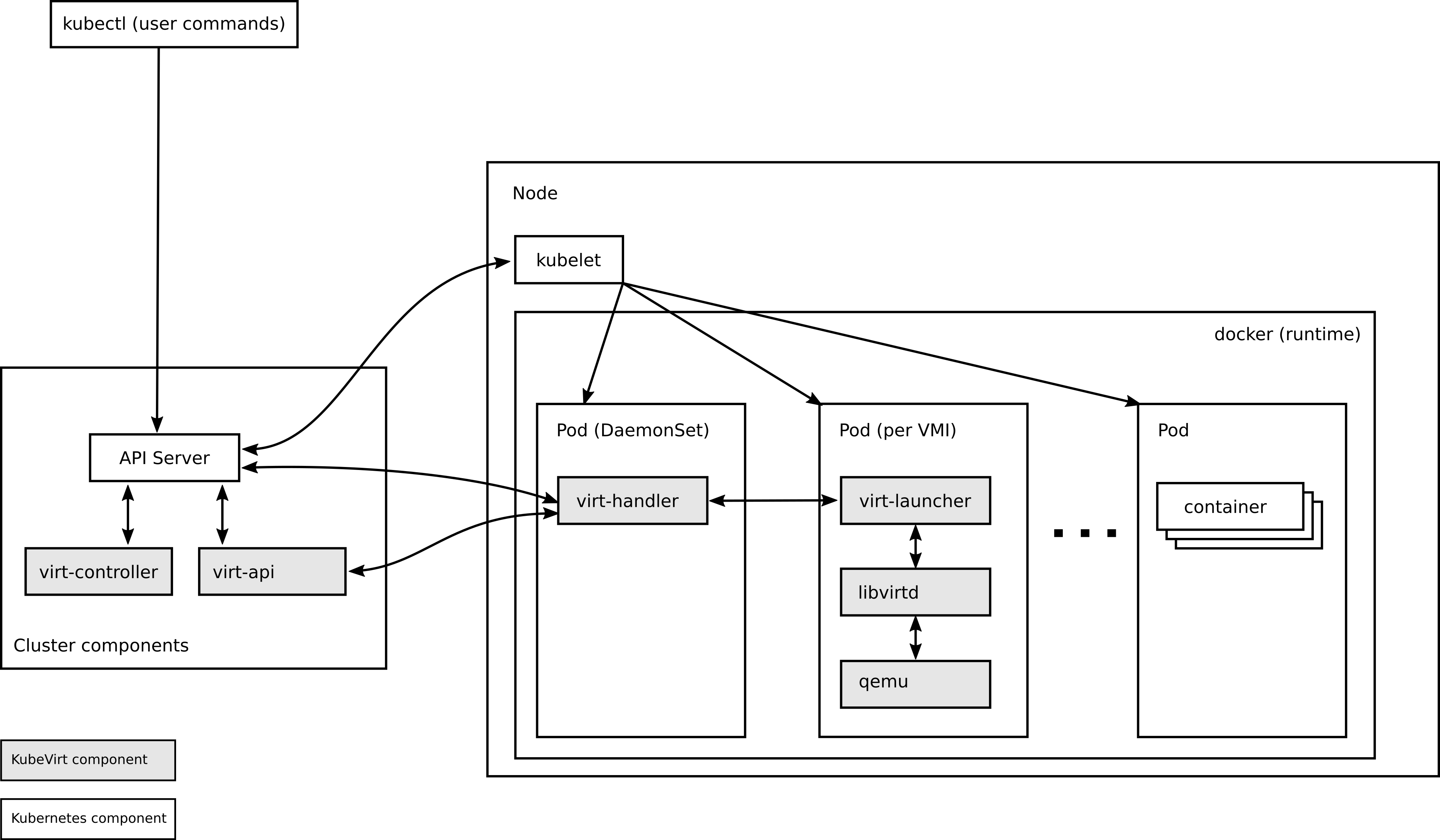
上篇,我们 从0开始装一套 KubeVirt 1.2.1
