
Etcd 概述及运维实践
Etcd 概述及运维实践

Etcd 概述
什么是 Etcd ?
Etcd 是 CoreOS 团队于2013年6月发起的开源项目,它的目标是构建一个高可用的分布式键值(key-value)数据库。etcd内部采用raft协议作为一致性算法,Etcd基于 Go 语言实现。
名字由来,它源于两个方面,unix的“/etc”文件夹和分布式系统(“D”istribute system)的D,组合在一起表示etcd是用于存储分布式配置的信息存储服务。
Kubernetes 为什么用 Etcd ?
2014年6月,Google 的 Kubernetes 项目诞生了,我们前面所讨论到 Go 语言编写、etcd 高可用、Watch 机制、CAS、TTL等特性正是 Kubernetes 所需要的,它早期的0.4版本,使用的正是 etcd v0.2版本。
Kubernetes 是如何使用 etcd v2 这些特性的呢?举几个简单小例子。
当你使用 Kubernetes 声明式 API 部署服务的时候,Kubernetes 的控制器通过 etcd Watch 机制,会实时监听资源变化事件,对比实际状态与期望状态是否一致,并采取协调动作使其一致。Kubernetes 更新数据的时候,通过 CAS 机制保证并发场景下的原子更新,并通过对 key 设置 TTL 来存储 Event 事件,提升Kubernetes 集群的可观测性,基于 TTL 特性,Event 事件 key 到期后可自动删除。
Kubernetes 项目使用etcd,除了技术因素也与当时的商业竞争有关。CoreOS 是 Kubernetes 容器生态圈的核心成员之一。
Etcd 版本变化
时间轴图,总结一下 etcd v1/v2 关键特性
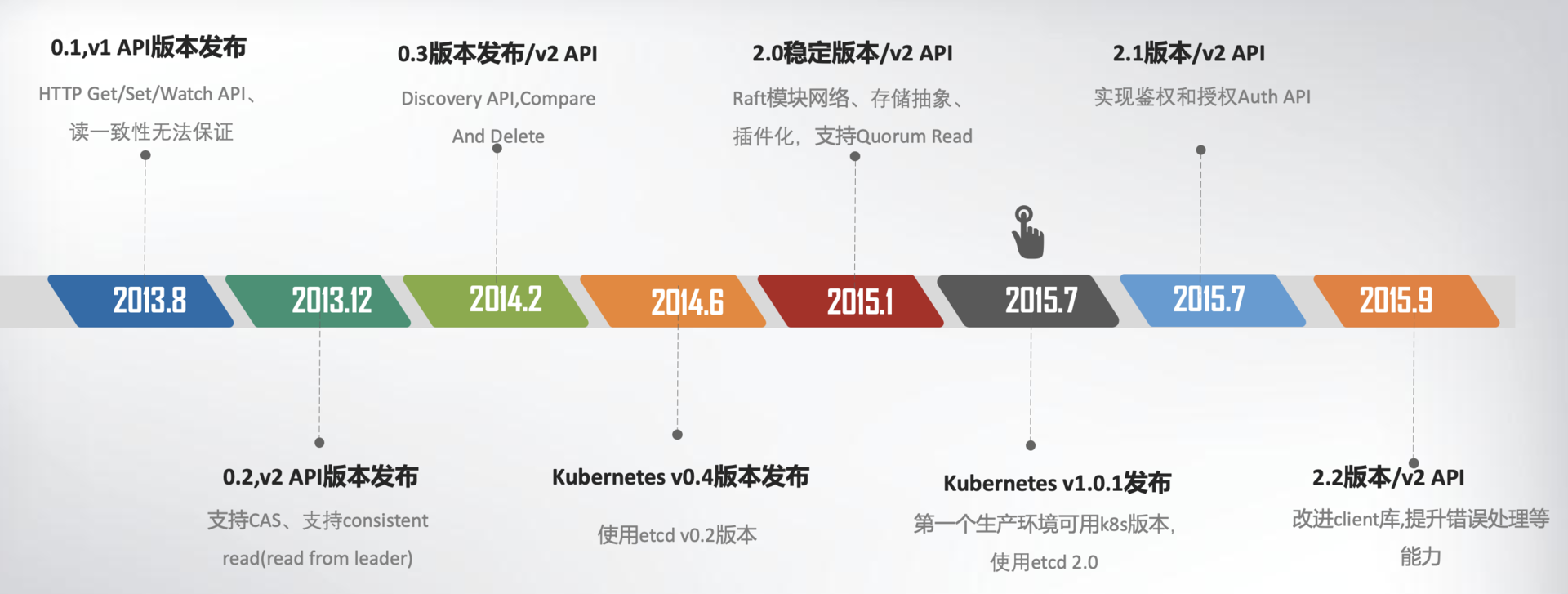
然而随着 Kubernetes 项目不断发展,v2 版本的瓶颈和缺陷逐渐暴露,遇到了若干性能和稳定性问题,Kubernetes 社区呼吁支持新的存储、批评 etcd 不可靠的声音开始不断出现。
问题如下

2016年6月,etcd 3.0 诞生,随后 Kubernetes 1.6 发布,默认启用 etcd v3,助力 Kubernetes 支撑5000节点集群规模。
时间轴及重要特性

发展到今天,在 GitHub 上 star 数超过46K。在 Kubernetes 的业务场景磨炼下它不断成长,走向稳定和成熟,成为技术圈众所周知的开源产品,而 v3方案的发布,也标志着 etcd 进入了技术成熟期,成为云原生时代的首选元数据存储产品。
基础架构

你可以看到,按照分层模型,etcd 可分为 Client 层、API 网络层、Raft 算法层、逻辑层和存储层。这些层的功能如下:
Client 层:Client 层包括 client v2 和 v3 两个大版本 API 客户端库,提供了简洁易用的 API,同时支持负载均衡、节点间故障自动转移,可极大降低业务使用etcd复杂度,提升开发效率、服务可用性。
API 网络层:API 网络层主要包括 client 访问 server 和 server 节点之间的通信协议。一方面,client 访问 etcd server 的 API 分为 v2 和 v3 两个大版本。v2 API 使用 HTTP/1.x 协议,v3 API 使用 gRPC 协议。同时 v3 通过 etcd grpc-gateway 组件也支持 HTTP/1.x 协议,便于各种语言的服务调用。另一方面,server 之间通信协议,是指节点间通过Raft算法实现数据复制和Leader选举等功能时使用的HTTP协议。
Raft 算法层:Raft 算法层实现了 Leader 选举、日志复制、ReadIndex 等核心算法特性,用于保障 etcd 多个节点间的数据一致性、提升服务可用性等,是etcd的基石和亮点。
功能逻辑层:etcd 核心特性实现层,如典型的 KVServer 模块、MVCC 模块、Auth 鉴权模块、Lease 租约模块、Compactor 压缩模块等,其中 MVCC 模块主要由 treeIndex 模块和 boltdb 模块组成。
存储层:存储层包含预写日志(WAL)模块、快照(Snapshot)模块、boltdb 模块。其中 WAL 可保障 etcd crash 后数据不丢失,boltdb 则保存了集群元数据和用户写入的数据。
概念术语
- Raft:etcd 所采用的保证分布式系统强一致性的算法。
- Node:一个 Raft 状态机实例。
- Member: 一个 etcd 实例。它管理着一个 Node,并且可以为客户端请求提供服务。
- Cluster:由多个 Member 构成可以协同工作的 etcd 集群。
- Peer:对同一个 etcd 集群中另外一个 Member 的称呼。
- Client: 向 etcd 集群发送 HTTP 请求的客户端。
- WAL:预写式日志,etcd 用于持久化存储的日志格式。
- snapshot:etcd 防止 WAL 文件过多而设置的快照,存储 etcd 数据状态。
- Proxy:etcd 的一种模式,为 etcd 集群提供反向代理服务。
- Leader:Raft 算法中通过竞选而产生的处理所有数据提交的节点。
- Follower:竞选失败的节点作为 Raft 中的从属节点,为算法提供强一致性保证。
- Candidate:当 Follower 超过一定时间接收不到 Leader 的心跳时转变为 Candidate 开始竞选。
- Term:某个节点成为 Leader 到下一次竞选时间,称为一个 Term。
- Index:数据项编号。Raft 中通过 Term 和 Index 来定位数据。
运维实践
etcdctl 常用命令
全局参数
ETCD_CA_CERT="/etc/kubernetes/pki/etcd/ca.crt"
ETCD_CERT="/etc/kubernetes/pki/etcd/server.crt"
ETCD_KEY="/etc/kubernetes/pki/etcd/server.key"
HOST_1=https://xxx.xxx.xxx.xxx:2379
使用示例
ETCDCTL_API=3 etcdctl --cacert="${ETCD_CA_CERT}" --cert="${ETCD_CERT}" --key="${ETCD_KEY}" \
--endpoints="${HOST_1}" endpoint status --write-out=table
常用命令
- 键值命令
# 增 & 改
put foo bar
# 查
get foo
# 根据前缀查询
get --prefix "/demo"
# 查询所有 keys
get --prefix "" --keys-only
# 删
del foo
# 事务,多个操作合并为一个事务
txn <<<'mod("key1") > "0"
put key1 "overwrote-key1"
put key1 "created-key1"
put key2 "some extra key"
'
# 压缩
compaction 1234
# 监听
watch foo
- 集群维护命令
# 列出成员
member list
# 端点健康情况
endpoint health
# 端点状态
endpoint status
# 告警列表
alarm list
# 解除所有告警
alarm disarm
# 碎片整理
defrag
# 创建快照进行备份
snapshot save snapshot.db
# 快照恢复
snapshot restore
# 快照状态
snapshot status
Etcd 监控
重点监控指标
指标分类
- 健康状态
- USE 方法(系统)
- 使用率
- 饱和度
- 错误
- RED 方法(应用)
- 请求速率
- 错误率
- 延迟
| 指标分类 | 指标 | 释义 |
|---|---|---|
| 健康状态 | 实例健康状态 | etcd是一个分布式系统,由多个成员节点组成。监控etcd成员节点的状态可以帮助你了解集群中节点的健康状况,发现掉线或者异常节点。 |
| 健康状态 | 主从状态 | |
| 健康状态 | etcd leader切换统计 | 频繁的领导者变更会严重影响 etcd 的性能。这也意味着领导者不稳定,可能是由于网络连接问题或对 etcd 集群施加的过载负荷导致的。 |
| 健康状态 | 心跳 | etcd集群中的节点通过发送心跳来保持彼此之间的连接。监控丢失的心跳可以帮助你发现etcd节点之间的通信问题或者网络延迟。 |
| RED 方法 | QPS | |
| RED 方法 | 请求错误率 | 监控etcd的错误率可以帮助你发现etcd操作中的潜在问题。高错误率可能表明集群遇到了故障或其他异常情况。 |
| RED 方法 | 请求延迟 | 监控etcd的请求延迟可以帮助你了解API请求的处理时间。较高的延迟可能表明etcd正面临负载压力或性能问题。 |
| RED 方法 | 磁盘同步(WAL/DB fsync)耗时 | 高磁盘操作延迟(wal_fsync_duration_seconds或backend_commit_duration_seconds)通常表示磁盘问题。它可能会导致高请求延迟或使群集不稳定。 |
| RED 方法 | 同步延迟 | 如果集群正常运行,已提交的提案应该随着时间的推移而增加。重要的是要在集群的所有成员中监控这个指标;如果单个成员与其领导节点之间存在持续较大的滞后,这表明该成员运行缓慢或存在异常。 |
| RED 方法 | 提案失败次数 | 失败的提案通常与两个问题相关:与领导选举相关的暂时性故障或由于集群丧失法定人数而导致的较长时间的停机。 |
| RED 方法 | 快照处理时间 | etcd定期创建快照以备份数据。监控快照处理时间可以帮助你了解etcd备份的性能,确保备份任务能够及时完成。 |
| RED 方法 | watcher 数量 | 监控etcd集群当前连接到etcd的客户端数量。如果连接数过高,可能需要调整etcd的配置或者增加集群的容量。 |
| USE 方法 | CPU 使用率 | |
| USE 方法 | 内存使用量 | |
| USE 方法 | 打开文件数 | |
| USE 方法 | 存储空间使用率 | 监控etcd存储空间的使用率可以帮助你确保etcd有足够的空间存储配置数据。如果使用率接近或达到上限,可能需要考虑扩展存储容量或者清理无用的数据。 |
使用 kube-prometheus 收集 etcd 指标
http 模式(推荐)
修改--listen-metrics-urls
#- --listen-metrics-urls=http://127.0.0.1:2381
- --listen-metrics-urls=http://127.0.0.1:2381,http://ip:2381
部署
helm install monitoring -n cattle-prometheus --set kubeEtcd.service.port=2381 --set kubeEtcd.service.targetPort=2381 --set prometheusOperator.admissionWebhooks.patch.image.sha=null ./
https 模式
新增 etcd secret
kubectl create secret generic etcd-certs -n cattle-prometheus --from-file=/etc/kubernetes/pki/etcd/ca.crt --from-file=/etc/kubernetes/pki/etcd/healthcheck-client.crt --from-file=/etc/kubernetes/pki/etcd/healthcheck-client.key
部署
helm install monitoring -n cattle-prometheus --set kubeEtcd.serviceMonitor.scheme=https --set kubeEtcd.serviceMonitor.caFile=/etc/prometheus/secrets/etcd-certs/ca.crt --set kubeEtcd.serviceMonitor.certFile=/etc/prometheus/secrets/etcd-certs/healthcheck-client.crt --set kubeEtcd.serviceMonitor.keyFile=/etc/prometheus/secrets/etcd-certs/healthcheck-client.key --set prometheus.prometheusSpec.secrets={etcd-certs} --set prometheusOperator.admissionWebhooks.patch.image.sha=null ./
大盘展示
Grafana 大盘: https://github.com/clay-wangzhi/grafana-dashboard/blob/master/etcd/etcd-dash.json
导入即可
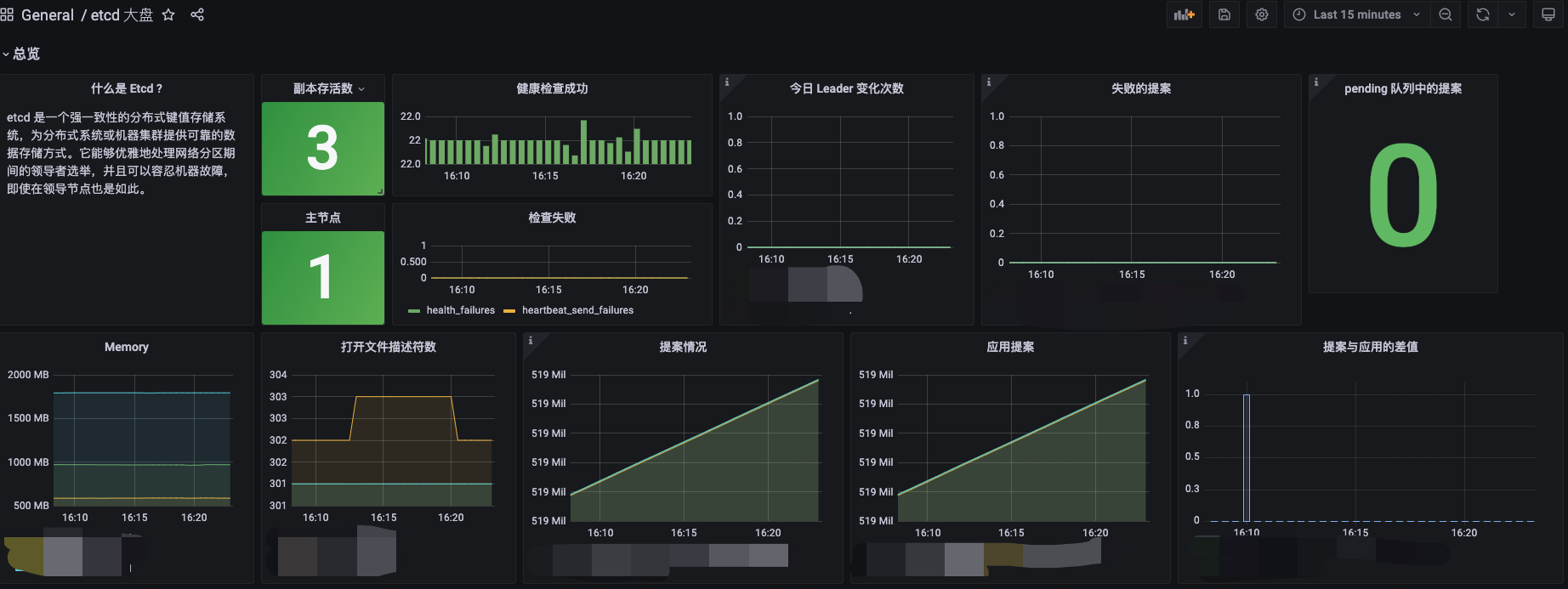
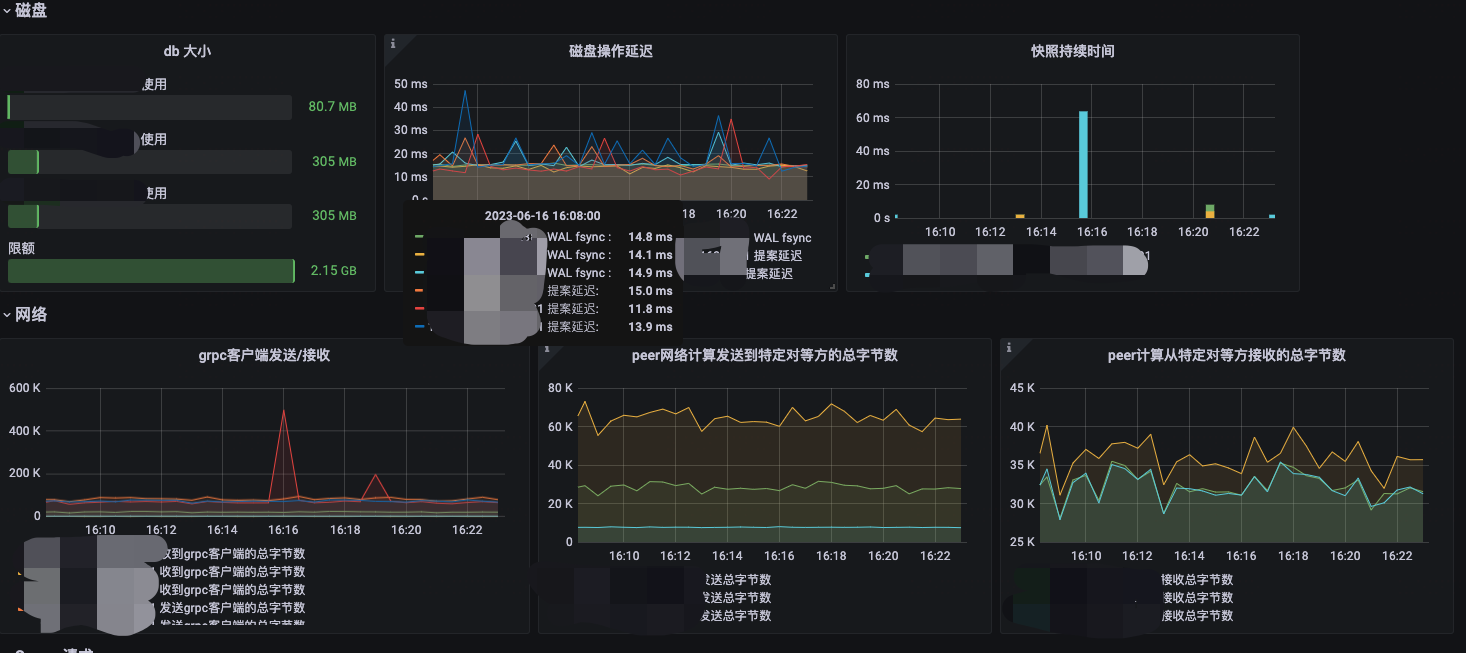
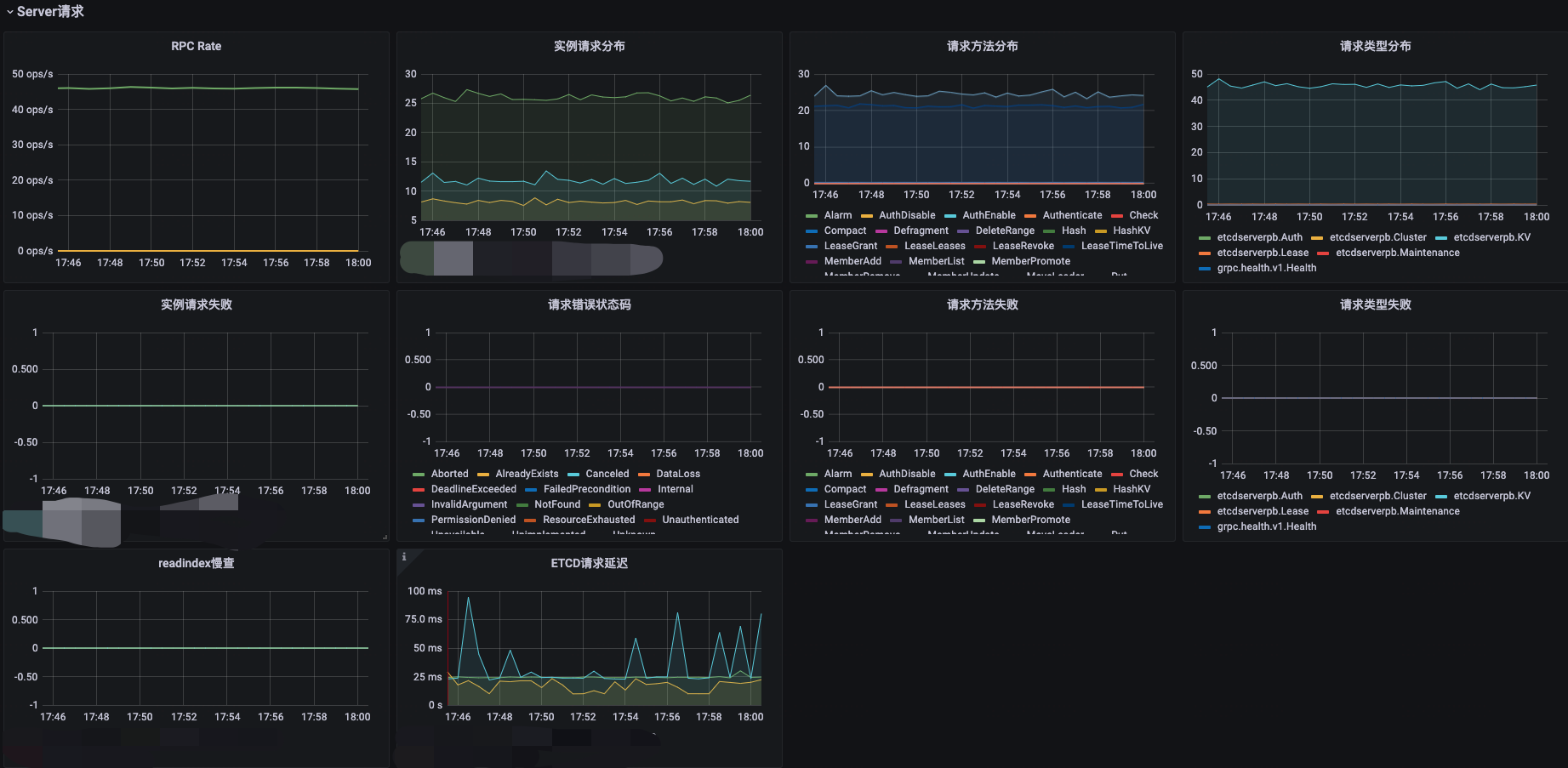
监控指标补充
- 数据一致性、写请求、资源对象数等

收集过程详见:https://github.com/clay-wangzhi/etcd-metrics
参考 https://github.com/kstone-io/kstone 进行裁剪
Etcd 基准测试
SLI & SLO
SLI(Service Level Indicator):服务等级指标,其实就是我们选择哪些指标来衡量我们的稳定性。
SLO(Service Level Objective):服务等级目标,指的就是我们设定的稳定性目标,比如“几个 9”这样的目标。
SLO 是 SLI 要达成的目标,我们需要选择合适的 SLI,设定对应的 SLO。
| SLI | SLO | 测试方式 |
|---|---|---|
| 吞吐量:衡量etcd每秒可以处理的请求数量 | 每秒处理40,000个读取请求和20,000个写入请求 | 官方 benchmark |
| 响应时间:衡量etcd对于读取和写入请求的响应时间 | 99%的读写请求在100毫秒以内完成 | 官方 benchmark |
目前已有 SLI 指标的收集、监控、展示及告警
使用 benchmark 测试延迟和吞吐量
环境准备
在 Linux 主机安装 Go 环境
下载解压
wget https://golang.google.cn/dl/go1.19.10.linux-amd64.tar.gz
tar -C /usr/local -xzf go1.19.10.linux-amd64.tar.gz
配置到PATH环境变量
在 /etc/profile 文件追加如下内容
export PATH=$PATH:/usr/local/go/bin
export GOPROXY=https://goproxy.cn
最后 source 生效
source /etc/profile
安装 benchmark 工具
clone 代码,安装 benchmark
git clone https://github.com/etcd-io/etcd.git --depth 1
cd etcd/
go install -v ./tools/benchmark
# 找到二进制文件位置
go list -f "{{.Target}}" ./tools/benchmark
基准测试
查看帮助
cd /root/go/bin/
./benchmark -h
配置变量
ETCD_CA_CERT="/etc/kubernetes/pki/etcd/ca.crt"
ETCD_CERT="/etc/kubernetes/pki/etcd/server.crt"
ETCD_KEY="/etc/kubernetes/pki/etcd/server.key"
HOST_1=https://xxx.xxx.xxx.xxx:2379
HOST_2=https://xxx.xxx.xxx.xxx:2379
HOST_3=https://xxx.xxx.xxx.xxx:2379
# 提前写个测试 key
YOUR_KEY=foo
ETCDCTL_API=3 /usr/local/bin/etcdctl --endpoints=${HOST_1},${HOST_2},${HOST_3} --cacert="${ETCD_CA_CERT}" --cert="${ETCD_CERT}" --key="${ETCD_KEY}" put $YOUR_KEY bar
写测试
# write to leader
./benchmark --endpoints=${HOST_2} --cacert="${ETCD_CA_CERT}" --cert="${ETCD_CERT}" --key="${ETCD_KEY}" --target-leader --conns=1 --clients=1 \
put --key-size=8 --sequential-keys --total=10000 --val-size=256
./benchmark --endpoints=${HOST_2} --cacert="${ETCD_CA_CERT}" --cert="${ETCD_CERT}" --key="${ETCD_KEY}" --target-leader --conns=100 --clients=1000 \
put --key-size=8 --sequential-keys --total=100000 --val-size=256
# write to all members
./benchmark --endpoints=${HOST_1},${HOST_2},${HOST_3} --cacert="${ETCD_CA_CERT}" --cert="${ETCD_CERT}" --key="${ETCD_KEY}" --conns=100 --clients=1000 \
put --key-size=8 --sequential-keys --total=100000 --val-size=256
| Number of keys | Key size in bytes | Value size in bytes | Number of connections | Number of clients | Target etcd server | Average write QPS | 99% latency per request |
|---|---|---|---|---|---|---|---|
| 10,000 | 8 | 256 | 1 | 1 | leader only | 154 | 14.8ms |
| 100,000 | 8 | 256 | 100 | 1000 | leader only | 14,567 | 134.4ms |
| 100,000 | 8 | 256 | 100 | 1000 | all members | 17,018 | 117ms |
读测试
# Single connection read requests
./benchmark --endpoints=${HOST_1},${HOST_2},${HOST_3} --cacert="${ETCD_CA_CERT}" --cert="${ETCD_CERT}" --key="${ETCD_KEY}" --conns=1 --clients=1 \
range $YOUR_KEY --consistency=l --total=10000
./benchmark --endpoints=${HOST_1},${HOST_2},${HOST_3} --cacert="${ETCD_CA_CERT}" --cert="${ETCD_CERT}" --key="${ETCD_KEY}" --conns=1 --clients=1 \
range $YOUR_KEY --consistency=s --total=10000
# Many concurrent read requests
./benchmark --endpoints=${HOST_1},${HOST_2},${HOST_3} --cacert="${ETCD_CA_CERT}" --cert="${ETCD_CERT}" --key="${ETCD_KEY}" --conns=100 --clients=1000 \
range $YOUR_KEY --consistency=l --total=100000
./benchmark --endpoints=${HOST_1},${HOST_2},${HOST_3} --cacert="${ETCD_CA_CERT}" --cert="${ETCD_CERT}" --key="${ETCD_KEY}" --conns=100 --clients=1000 \
range $YOUR_KEY --consistency=s --total=100000
| Number of requests | Key size in bytes | Value size in bytes | Number of connections | Number of clients | Consistency | Average read QPS | 99% latency per request |
|---|---|---|---|---|---|---|---|
| 10,000 | 8 | 256 | 1 | 1 | Linearizable | 509 | 7.3ms |
| 10,000 | 8 | 256 | 1 | 1 | Serializable | 1,709 | 1.7ms |
| 100,000 | 8 | 256 | 100 | 1000 | Linearizable | 29,326 | 104.8ms |
| 100,000 | 8 | 256 | 100 | 1000 | Serializable | 43,469 | 98.9ms |
使用 FIO 测试磁盘性能
Etcd 对内存和 CPU 消耗并不高,足够就行。
一次 Etcd 请求的最小时间 = 成员节点之间的网络往返时延 + 收到数据之后进行持久化的时延。因此,Etcd 的性能主要受两方面的约束:
- 网络
- 磁盘
多节点的 Etcd 集群成员节点应该尽量部署在同一个数据中心,减少网络时延。同一数据中心内,不同节点的网络情况通常是非常好的,如果需要测试可以使用 ping 或 tcpdump 命令进行分析。
下面主要讨论硬盘 IO 测试方法。
存储性能能够满足 etcd 的性能要求,有两种方法测试:
已运行的 etcd 集群,通过指标
etcd_disk_wal_fysnc_duration_seconds来评估存储 I/O 性能, 该指标记录了 WAL 文件系统调用 fsync 的延迟分布,当 99% 样本的同步时间小于 10 毫秒就可以认为存储性能能够满足 etcd 的性能要求。是用 fio 命令,还原 etcd 使用场景,看99线
mkdir test-data fio --rw=write --ioengine=sync --fdatasync=1 --directory=test-data --size=22m --bs=2300 --name=mytest
调优
磁盘
换 SSD 盘 -------- 这个是必须的
给定较高的磁盘优先级
# best effort, highest priority
$ sudo ionice -c2 -n0 -p `pgrep etcd`
CPU
CPU 性能模式调整为 performance , 如何调整不成功参考:https://clay-wangzhi.com/cloudnative/troubleshooting/vm-vs-container-performance.html#cpu
echo performance | tee /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor
配置参数
开启自动压缩、修改etcd raft消息最大字节数、修改 etcd最大容量等。
参考链接:
etcd 实战课 | 极客时间 唐聪:https://time.geekbang.org/column/intro/100069901
github etcdctl doc:https://github.com/etcd-io/etcd/blob/main/etcdctl/README.md
datadog etcd 指标:https://docs.datadoghq.com/integrations/etcd/?tab=host
etcd 官方文档-tunning:https://etcd.io/docs/v3.5/tuning/
etcd 官方文档-硬件要求:https://etcd.io/docs/v3.5/op-guide/hardware/
etcd 官方文档-benchmark:https://etcd.io/docs/v3.5/benchmarks/etcd-3-demo-benchmarks/
使用fio测试etcd是否满足要求:https://www.ibm.com/cloud/blog/using-fio-to-tell-whether-your-storage-is-fast-enough-for-etcd
我是 Clay,下期见 👋
欢迎订阅我的公众号「SRE运维进阶之路」或关注我的 Github https://github.com/clay-wangzhi/wiki 查看最新文章
欢迎加我微信
sre-k8s-ai,与我讨论云原生、稳定性相关内容
