
Rook-Ceph 安装配置
Rook-Ceph 安装配置
在容器世界中,无状态是一个核心原则,然而我们始终需要保存数据,并提供给他人进行访问。所以就需要一个方案用于保持数据,以备重启之需。
在 Kubernetes 中,PVC 是管理有状态应用的一个推荐方案。有了 PVC 的帮助,Pod 可以申请并连接到存储卷,这些存储卷在 Pod 生命周期结束之后,还能独立存在。
PVC 在存储方面让开发和运维的职责得以分离。运维人员负责供应存储,而开发人员则可以在不知后端细节的情况下,申请使用这些存储卷。
PVC 由一系列组件构成:
PVC:是 Pod 对存储的请求。PVC 会被 Pod 动态加载成为一个存储卷。
PV,可以由运维手工分配,也可以使用
StorageClass动态分配。PV 受 Kubernetes 管理,但并不与特定的 Pod 直接绑定。StorageClass:由管理员创建,可以用来动态的创建存储卷和 PV。
物理存储:实际连接和加载的存储卷。
分布式存储系统是一个有效的解决有状态工作负载高可用问题的方案。Ceph 就是一个分布式存储系统,近年来其影响主键扩大。Rook 是一个编排器,能够支持包括 Ceph 在内的多种存储方案。Rook 简化了 Ceph 在 Kubernetes 集群中的部署过程。
在生产环境中使用 Rook + Ceph 组合的用户正在日益增加,尤其是自建数据中心的用户,CENGN、Gini、GPR 等很多组织都在进行评估。

Ceph & Rook 简介
Ceph 是什么
Ceph 是一个分布式存储系统,具备大规模、高性能、无单点失败的特点。Ceph 是一个软件定义的系统,也就是说他可以运行在任何符合其要求的硬件之上。
Ceph 包括多个组件:
Ceph Monitors(MON):负责生成集群票选机制。所有的集群节点都会向 Mon 进行汇报,并在每次状态变更时进行共享信息。
Ceph Object Store Devices(OSD):负责在本地文件系统保存对象,并通过网络提供访问。通常 OSD 守护进程会绑定在集群的一个物理盘上,Ceph 客户端直接和 OSD 打交道。
Ceph Manager(MGR):提供额外的监控和界面给外部的监管系统使用。
Reliable Autonomic Distributed Object Stores:Ceph 存储集群的核心。这一层用于为存储数据提供一致性保障,执行数据复制、故障检测以及恢复等任务。
为了在 Ceph 上进行读写,客户端首先要联系 MON,获取最新的集群地图,其中包含了集群拓扑以及数据存储位置的信息。Ceph 客户端使用集群地图来获知需要交互的 OSD,从而和特定 OSD 建立联系。
Rook 是什么
Rook 是一个可以提供 Ceph 集群管理能力的 Operator。Rook 使用 CRD 一个控制器来对 Ceph 之类的资源进行部署和管理。
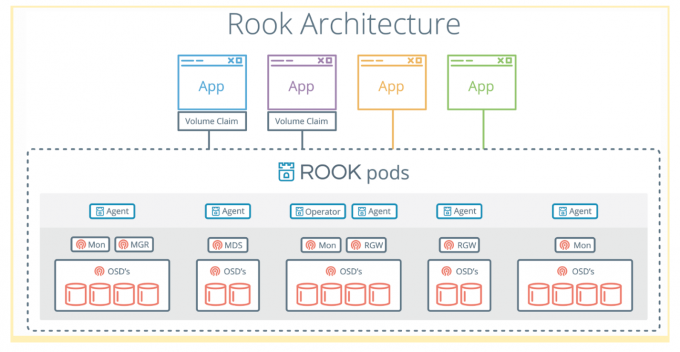
Rook 包含多个组件:
Rook Operator:Rook 的核心组件,Rook Operator 是一个简单的容器,自动启动存储集群,并监控存储守护进程,来确保存储集群的健康。
Rook Agent:在每个存储节点上运行,并配置一个 FlexVolume 插件,和 Kubernetes 的存储卷控制框架进行集成。Agent 处理所有的存储操作,例如挂接网络存储设备、在主机上加载存储卷以及格式化文件系统等。
Rook Discovers:检测挂接到存储节点上的存储设备。
Rook 还会用 Kubernetes Pod 的形式,部署 Ceph 的 MON、OSD 以及 MGR 守护进程。
Rook Operator 让用户可以通过 CRD 的是用来创建和管理存储集群。每种资源都定义了自己的 CRD.
Rook Cluster:提供了对存储机群的配置能力,用来提供块存储、对象存储以及共享文件系统。每个集群都有多个 Pool。
Pool:为块存储提供支持。Pool 也是给文件和对象存储提供内部支持。
Object Store:用 S3 兼容接口开放存储服务。
File System:为多个 Kubernetes Pod 提供共享存储。
在 Kubernetes 上部署 Rook
前提条件
您已经安装了 Kubernetes 集群,且集群版本不低于 v1.17.0
Kubernetes 集群有至少 3 个工作节点,且每个工作节点都有一块初系统盘以外的 未格式化 的裸盘(工作节点是虚拟机时,未格式化的裸盘可以是虚拟磁盘),用于创建 3 个 Ceph OSD;
也可以只有 1 个工作节点,挂载了一块 未格式化 的裸盘;
在节点机器上执行
lsblk -f指令可以查看磁盘是否需被格式化,输出结果如下:lsblk -f NAME FSTYPE LABEL UUID MOUNTPOINT vda └─vda1 LVM2_member eSO50t-GkUV-YKTH-WsGq-hNJY-eKNf-3i07IB ├─ubuntu--vg-root ext4 c2366f76-6e21-4f10-a8f3-6776212e2fe4 / └─ubuntu--vg-swap_1 swap 9492a3dc-ad75-47cd-9596-678e8cf17ff9 [SWAP] vdb如果
FSTYPE字段不为空,则表示该磁盘上已经被格式化。在上面的例子中,可以将磁盘vdb用于 Ceph 的 OSD,而磁盘vda及其分区则不能用做 Ceph 的 OSD。
安装
git clone --single-branch --branch v1.6.7 https://github.com/rook/rook.git
cd rook/cluster/examples/kubernetes/ceph
kubectl create -f crds.yaml -f common.yaml -f operator.yaml
# 修改 cluster.yaml 文件, dashboard 不使用 ssl
kubectl create -f cluster.yaml
# 创建 共享文件系统
kubectl create -f filesystem.yaml
# 提供存储
kubectl create -f csi/cephfs/storageclass.yaml
Rook 工具箱 & dashboard
1)安装 Rook
要验证集群是否处于正常状态,我们可以使用 Rook 工具箱 来运行 ceph status 命令查看。
# 部署 tools:
kubectl apply -f toolbox.yaml
一旦 toolbox 的 Pod 运行成功后,我们就可以使用下面的命令进入到工具箱内部进行操作:
kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l "app=rook-ceph-tools" -o jsonpath='{.items[0].metadata.name}') bash
比如现在我们要查看集群的状态,需要满足下面的条件才认为是健康的:
- 所有 mons 应该达到法定数量
- mgr 应该是激活状态
- 至少有一个 OSD 处于激活状态
- 如果不是 HEALTH_OK 状态,则应该查看告警或者错误信息
$ ceph status
ceph status
cluster:
id: dae083e6-8487-447b-b6ae-9eb321818439
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 15m)
mgr: a(active, since 2m)
osd: 31 osds: 2 up (since 6m), 2 in (since 6m)
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 79 GiB used, 314 GiB / 393 GiB avail
pgs:
如果群集运行不正常,可以查看 Ceph 常见问题以了解更多详细信息和可能的解决方案。
2)部署 dashboard:
kubectl apply -f dashboard-external-http.yaml
dashboard 的密码可以通过如下方式获取:
kubectl -n rook-ceph get secret rook-ceph-dashboard-password -o jsonpath="{['data']['password']}" | base64 --decode && echo
问题
错误一
错误信息:
Kubernetes安装rook-ceph集群时报MountVolume.SetUp failed for volume “rook-ceph-crash-collector-keyring” : secret “rook-ceph-crash-collector-keyring” not found
解决办法:
删除yaml的创建
kubectl delete -f cluster.yaml kubectl delete -f operator.yaml kubectl delete -f common.yaml kubectl delete -f crds.yaml确认目录下有文件
ll /var/lib/rook/ /var/lib/kubelet/plugins/ /var/lib/kubelet/plugins_registry/删除之前失败的创建
rm -rf /var/lib/rook/* /var/lib/kubelet/plugins/* /var/lib/kubelet/plugins_registry/*⚠️ 在每个相关节点都执行
重新创建集群
错误二
错误信息:
waiting for a volume to be created, either by external provisioner "ceph.rook.io/block" or manually created by system administrator解决办法:
因为自己编写了 pool 和 sc,直接 apply 官方的 rbd 目录里的 stoageclass.yaml
错误三
错误信息:
$ ceph -s cluster: id: f1731b79-1e9e-447e-9bc4-36b834c19582 health: HEALTH_WARN mons are allowing insecure global_id reclaim services: mon: 3 daemons, quorum bxpp-master-1,bxpp-worker-1,bxpp-worker-2 (age 25m) mgr: bxpp-worker-1(active, since 17m), standbys: bxpp-master-1, bxpp-worker-2 mds: cephfs:1 {0=bxpp-master-1=up:active} 2 up:standby osd: 3 osds: 3 up (since 16m), 3 in (since 16m) rgw: 3 daemons active (bxpp-master-1.rgw0, bxpp-worker-1.rgw0, bxpp-worker-2.rgw0) task status: scrub status: mds.bxpp-master-1: idle data: pools: 6 pools, 168 pgs objects: 211 objects, 4.1 KiB usage: 328 MiB used, 15 GiB / 15 GiB avail pgs: 168 active+clean错误原因:低版本bug
解决办法:
升级版本
或者直接禁用掉此设置(测试环境可)
ceph config set mon mon_warn_on_insecure_global_id_reclaim_allowed false ceph config set mon auth_allow_insecure_global_id_reclaim false
错误四
错误信息:
# ceph -s cluster: id: dd1a1ab2-0f34-4936-bc09-87bd40ef5ca0 health: HEALTH_WARN Degraded data redundancy: 183/4019 objects degraded (4.553%), 15 pgs degraded, 16 pgs undersized services: mon: 3 daemons, quorum k8s-01,k8s-02,k8s-03 mgr: k8s-01(active) mds: cephfs-2/2/2 up {0=k8s-01=up:active,1=k8s-03=up:active}, 1 up:standby osd: 5 osds: 5 up, 5 in rgw: 3 daemons active data: pools: 6 pools, 288 pgs objects: 1.92 k objects, 1020 MiB usage: 7.5 GiB used, 342 GiB / 350 GiB avail pgs: 183/4019 objects degraded (4.553%) 272 active+clean 15 active+undersized+degraded 1 active+undersized错误原因:这个状态降级的集群可以正常读写数据,undersized是当前存活的PG副本数为2,小于副本数3.将其做此标记,表明存数据副本数不足。
解决办法:
设置存储池的副本数为2
ceph osd pool set default.rgw.log size 2